深入剖析Parquet文件
前言
大规模分析型数据处理,在互联网公司乃至整个行业中已经被越来越广泛应用。当前大数据架构,通过开源的 GFS 和 MapReduce 实现的Hadoop,有着非常强的伸缩性,单个集群就可以伸缩到上千、乃至上万个节点。这上千个节点使用廉价的PC架构搭建,用来收集和存储海量的业务数据。这些业务数据,包含不同的数据类型、以及不同的存储方式。
比如spark就提供一套完整API接口,用于方便读写不同格式外部数据源数据。

下面,让我们先来了解这些最基础的概念,便于我们深入学习。
数据类型
非结构化
非结构化数据是指数据不规则或不完整,没有预定义的数据模型,因此不适合主流关系数据库。由于没有易于识别的结构,因此很难被计算机程序读取,解析它需要很高的开销
非结构化数据的一些来源包括:
-
网页
-
影片
-
用户对博客和社交媒体网站的评论
-
备忘录
-
报告
-
调查回复
-
文档(Word、PPT、PDF、文本)
-
非结构化文本
-
客户服务电话记录
-
互联网上的图片(JPEG、PNG、GIF 等)
-
媒体日志
半结构化
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。
半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。
常见的半结构数据有XML和JSON
XML:
<person>
<name>A</name>
<age>13</age>
<gender>female</gender>
</person>
JSON:
{"name":"A", "age":13, "gender": "female"}
结构化
结构化格式具有最少的解析开销和最有效的存储。我们有行和列的概念以及定义良好的模式。比如使用关系型数据表示和存储:数据以行为单位,一行数据表示一个实体信息,每一行的数据属性是相同的。
+------+------+------+
| id | name | age |
+------+------+------+
| 1 | aaa | 30 |
| 2 | bbb | 15 |
+------+------+------+
所以,结构化的数据存储和排列是很有规律的,这对查询和修改等操作很有帮助。
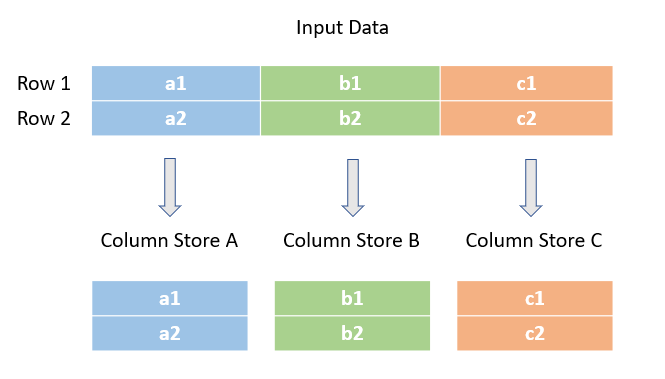
存储模型
现在,我们有一份按行、列的二维表的形式存储的逻辑数据库,总共存储6条数据, 如下图:
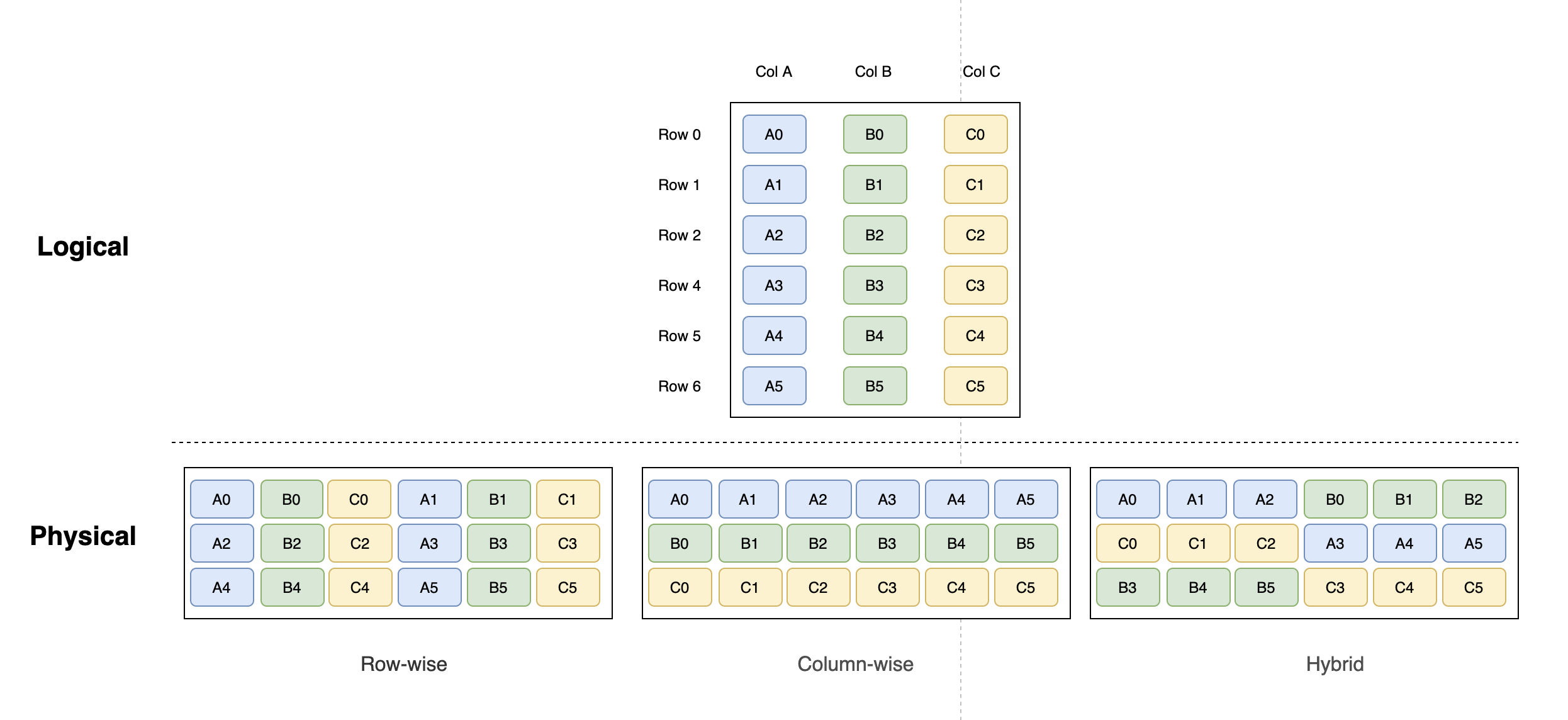
行式存储(水平分区)
在行式数据库中,每一行中的每一块数据都是紧挨着另一块数据存放在硬盘中。一般情况下,你可以认为每一行存贮的内容就是硬盘中的一组连续的字节。行式存储擅长随机读操作,适合于OLTP场景,像SQL server、Oracle、mysql等传统的是属于行式数据库范畴。
行式存储适用场景:
- 随机增删改查操作
- 表的字段个数比较少,查询大部分字段
- 需要频繁的插入或更新操作,其操作与索引和行的大小有关联性
通常,行式数据库在读取数据时,会存在一个固有的“缺陷”。比如,所选择查询的数据只涉及到少数列,但由于这么数据存储在各行数据单元中,应用程序必须完整读取每一条完整的行记录,从而使得读取效率大大降低。对此,行式数据库优化方式是通过给字段添加“索引”或者给分库分表等手段。
列式存储(垂直分区)
列式存储(Column-based)是相对于行式存储来说的。在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。适用于 OLAP 场景,像大数据HBase就属于列式存储。列式数据库基准测试的结论都是在查询分析场景下列式存储比行式存储快一个数量级。
当一行数据有 100 个字段,而我们的分析程序只需要其中 5 个字段的时候,就很尴尬了。因为如果我们顺序解析读取数据,我们就要白白多读 20 倍的数据
列式存储适用场景:
- 如果表的字段比较多(即大宽表),查询中涉及到列不很多的情况下,适合列存储
- 可在数据列中高效查找数据,无需维护索引(任何列都能作为索引),查询过程中能够尽量减少无关IO,避免全表扫描;
- 存在大量相同的数据,通过压缩后的数据量更小,可以减少硬盘存储空间,同时硬盘的数据量变少在读取时就可以减少 I/O 压力
可以看到列式存储解决了行式存储存在的问题。相比行式存储,列式存储又存在如下场景并不适用:
- 数据需要频繁更新的场景
- 表中列属性较少的小量数据库场景
- 不适合做含有删除和更新的实时操作
行列混存
可见,行式存储和列式存储各有优缺点,那么有没有一种存储方式能兼顾行式存储及列式存储的优点呢?
行列混存就是这样一种模式,该模式非常适合快速读取数据,而且如果想进行更新或插入,它可以轻松识别记录的位置。通常,将多行数据定义为一个数据块、每个数据块又包含多个列块,列块的个数等于列数。
Parquet和ORC就是适用行列混存
Parquet
Parquet 遵循行列混存模型,是 Spark/Hadoop 生态系统中最常用的格式之一。它是面向分析型业务的列式存储格式,、由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目。
Parquet 的设计与计算框架、数据模型以及编程语言无关,可以与任意项目集成,因此应用广泛。目前已经是 Hadoop 大数据生态圈列式存储的事实标准,目前能够与 Parquet 配合的组件有:
-
查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
-
计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
-
数据模型: Avro, Thrift, Protocol Buffers, POJOs
数据模型
想要深入的了解 Parquet 存储格式首先需要理解它的数据模型。Parquet 采用了一个类似 Google Protobuf 的协议来描述存储数据的 schema。如下是 Parquet 数据 schema 的一个简单示例:
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}
这个 schema 中每条记录表示一个人的 AddressBook。有且只有一个 owner,owner 可以有 0 个或者多个 ownerPhoneNumbers,owner 可以有 0 个或者多个 contacts。每个 contact 有且只有一个 name,这个 contact 的 phoneNumber 可有可无。这个 schema 可以用下图树结构表示
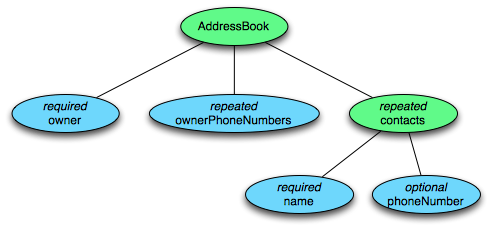
schema 的最上层是 message,里面可以包含一系列字段。每个字段都拥有 3 个属性:重复性(repetition)、类型(type)以及名称(name)。字段类型可以是一个 group 或者原子类型(如 int、boolean、string 等),group 可以用来表示数据的嵌套结构。字段的重复性有三种情况:
- required:有且只有一次
- optional:0 或 1 次
- repeated:0 或多次
这个模型非常的简洁。一些复杂的数据类型如:Map、List 和 Set 也可以用重复的字段(repeated fields) + groups 来表达,因此也就不用再单独定义这些类型。
文件的存储格式
我们知道parquet数据模型,那么如果把每个 AddressBook 对象按照列式存储格式存储下来呢?
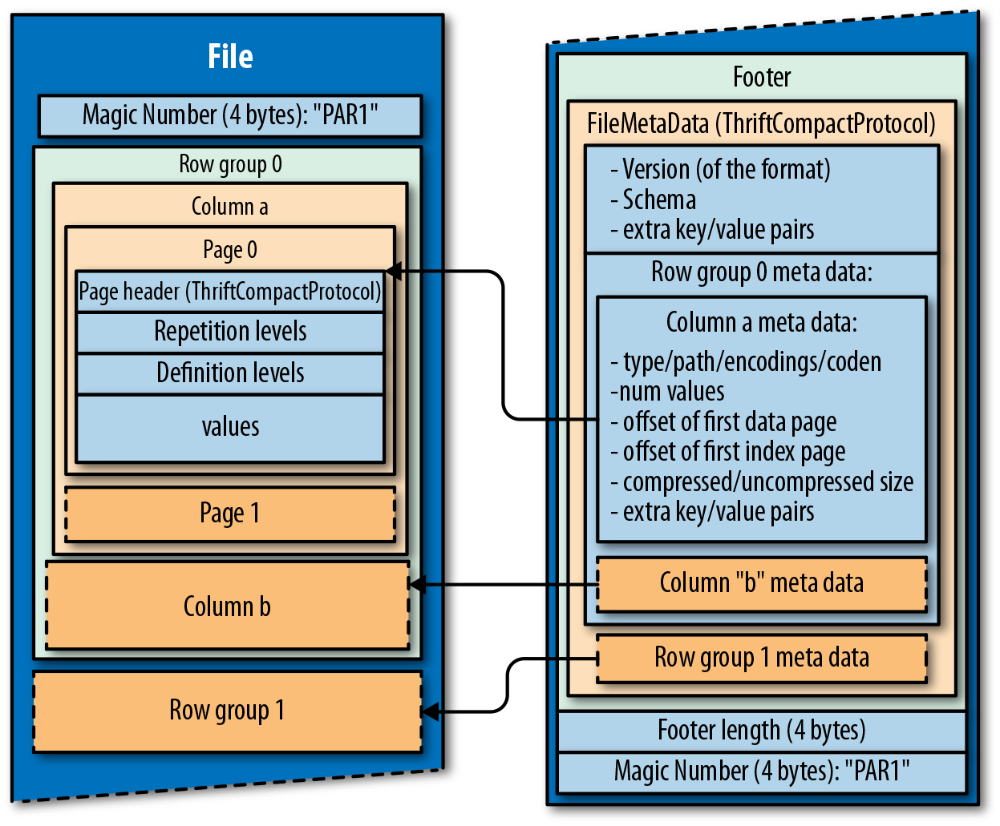
现在假定,我们需要存储一张二维表数据,行数据10000条、列数据100,数据总大小1G,存储在一个parquet文件中。那么Parquet文件在磁盘上又是如何分布?如下图:
-
一个Parquet文件的内容由Header,Data Block和Footer三部分组成,在文件的首尾各有一个内容为PAR1的Magic Number,用于标识这个文件为Parquet文件,Header部分就是开头Magic Number
-
Data Block是具体存放数据的区域,所有的数据按照水平分区切分成多个Row group,spark中Row group默认按照128MB进行切分。一个1G大小的parquet文件有10000条行数据,那么将有10个行组,每个行组假定按照平均分别包含1000条行数据
-
一个Row Group做为一个数据块,通过垂直分区切分成多个column Chunk,每个colum chunk负责存储某一列的数据,这些数据是这一列的 Repetition levels, Definition levels 和 values。比如,如果一张表有100个列,那么将有100个column chunk
-
一个column chunk是有多个Page组成,数据按照Page为最小单元来存储,根据内容分为Data Page 和 Dictionary Page,spark中Page默认按照1M进行切分,Page 是压缩和编码的单元
-
Footer部分由File Metadata,Footer Length,和Magic Number三部分组成。Foot Length是一个4字节的数据,用于标识Footer的大小,帮助找到Footer的起始指针位置。Magic Number同样是PAR1。File Metadata包含了重要的信息,包括Schema和每个Row Group的Metadata。每个Row Group 的Metadata又由各个Column的Metadata组成,每个Column Metadata包含了其Encoding,Offset,Statistics信息等
编码方式
parquet设计目的是用来处理大量数据,因此编码主要用于更有效地存储数据。在parquet文档中包含许多的编码方式,但实际上parquet只应用了两种编码:普通编码(Plain Encodig)和字典编码(Dictionary Encoding)。只能设置开 Dictionary 或者不开 Dictionary。而且只支持文件粒度的设置,不支持列粒度的,不能对某一具体列设置编码。
例如,初始化 ParquetWriter 时选择是否打开 Dictionary Encoding(enableDictionary 参数),默认为true。
/**
* public static final boolean DEFAULT_IS_DICTIONARY_ENABLED = true;
*
* public static final boolean DEFAULT_IS_DICTIONARY_ENABLED =
* ParquetProperties.DEFAULT_IS_DICTIONARY_ENABLED;
*/
@Deprecated
public ParquetWriter(Path file, WriteSupport<T> writeSupport, CompressionCodecName compressionCodecName, int blockSize, int pageSize) throws IOException {
this(file, writeSupport, compressionCodecName, blockSize, pageSize,
DEFAULT_IS_DICTIONARY_ENABLED, DEFAULT_IS_VALIDATING_ENABLED);
}
@Deprecated
public ParquetWriter(
Path file,
ParquetFileWriter.Mode mode,
WriteSupport<T> writeSupport,
CompressionCodecName compressionCodecName,
int blockSize,
int pageSize,
int dictionaryPageSize,
boolean enableDictionary,
boolean validating,
WriterVersion writerVersion,
Configuration conf) throws IOException {
this(HadoopOutputFile.fromPath(file, conf),
mode, writeSupport, compressionCodecName, blockSize,
validating, conf, MAX_PADDING_SIZE_DEFAULT,
ParquetProperties.builder()
.withPageSize(pageSize)
.withDictionaryPageSize(dictionaryPageSize)
.withDictionaryEncoding(enableDictionary)
.withWriterVersion(writerVersion)
.build(), null);
}
普通编码(Plain)
它适用于所有Parquet支持的类型,值被背对背编码,并在没有更有效的编码时,会用普通编码替代。
普通编码总是为给定类型保存相同数量的位置。例如,一个32位的int将始终存储在4个字节中。下图显示了从 0 到 3 的数字将如何使用普通编码进行存储:
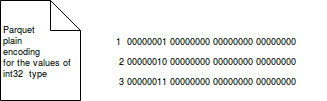
可见,普通编码简单又易于理解。但是普通编码存在空间浪费问题。比如,我们要存储1~99数,那么我们最多只能用到7位存储这个列(99用二进制表示为1100011)。
字典编码(Dictionary Encoding)
这种编码方案主要使用字典压缩来存储数据,当我们有复制或重复的值时,它可以节省大量内存。字典编码构建给定列中遇到的值的字典。字典将存储在每个列块的字典页中。这些值使用RLE/Bit-Packing Hybrid编码存储为整数。如果字典变得太大,无论是大小还是不同值的数量,编码都会回退到普通编码。字典页首先写入,在列块的数据页之前。
- RLE是Run-Length Encoding的缩写。它非常适合重复数据。它不是对值进行背对背编码,而是检测给定值连续出现了多少次(这种出现称为数据运行). 后来,它将给定值编码为:重复次数和值。当编码数据包含大量数据运行时,它非常有效,如下图:

-
Bit-packing基于这样的假设,即每个 int32 或 int64 值并不总是需要所有 32 位或 64 位。因此,位打包不是将这些值存储在它们的完整范围内,而是将多个值打包到一个空间中。这些值从每个字节的最低有效位到最高有效位打包。最低有效位是以二进制格式表示的一系列数字中的最低位。它位于图示的最右侧。用于打包值的公式使用按位运算。例如,要将位宽为 3 的 0 到 7 的数字打包,它使用以下位运算:
# 位宽为 3 输出[0] = ((输入[0] & 7) | ((输入[1] & 7) << 3) | ((输入[2] & 7) << 6)) & 255 输出[1] = (((输入[2] & 7) >>> 2) | ((输入[3] & 7) << 1) | ((输入[4] & 7) << 4)) | ((输入[5] & 7) << 7)) & 255 输出[2] = (((输入[5] & 7) >>> 1) | ((输入[6] & 7) << 2) | ((输入[7] & 7) << 5)) & 255
下图显示了数组第一个元素的生成:
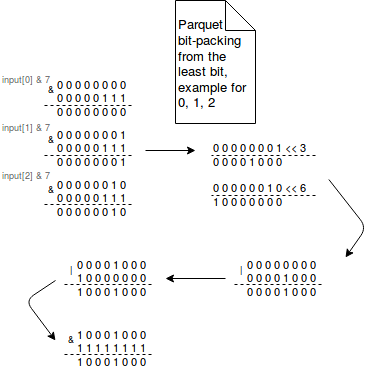
-
delta - 此编码可用于整数(int32 和 int64)或字节数组。以整数为例,这种方法很容易理解。以下代码段显示了如何对十进制值进行编码:
to_encode = [1, 2, 5, 7, 9] 编码 = [1, 1, 3, 2, 2]正如您简单推断的那样,增量编码对第一个值进行编码,然后对后续条目之间的差异进行编码。但在 Parquet 中,格式有点不同。它首先存储包含块大小、小块计数(每个具有编码值的块由多个小块组成)的标头、值的数量,最后是第一个值。后来每个迷你块由最小增量和编码字节的位宽组成。
增量编码可以显示日期时间列非常有效,例如以毫秒为单位存储,其中仅保存后续事件之间的差异,而不是每次占用 64 位的每个值。在全球范围内,建议在变化远小于绝对值的情况下使用。
那是针对整数的,但是对于二进制尤其是文本值呢?这里使用的增量编码也称为
增量编码
,对于具有公共前缀或后缀的有序字符串非常有效,例如在字典中。举个具体的例子:
to_encode = [abc, abcd, abcde, abcdef] 编码 = [abc, 3d, 4e, 5e, 6f]如图所示,增量编码存储第一个值,然后仅保存与不同字符连接的公共前缀对应的数字。
Parquet写数据
构建文件写header头
每次需要新生成一个parquet文件写入时,先构建parquet写文件类
// 构建parquet写文件类
ParquetWriter<Group> writer = ExampleParquetWriter.builder(file)
.config(GroupWriteSupport.PARQUET_EXAMPLE_SCHEMA, SCHEMA.toString())
.withCompressionCodec(compressionCodecName)
.build()
在构造函数中写入header头信息,详见代码:ParquetFileWriter.start()被构造函数new ParquetWriter()调用
public void start() throws IOException {
state = state.start();
LOG.debug("{}: start", out.getPos());
byte[] magic = MAGIC;
if (null != fileEncryptor && fileEncryptor.isFooterEncrypted()) {
magic = EFMAGIC;
}
// 每次写parquet文件时,header头写入Magic Number
out.write(magic);
}
写入一行行数据
parquet通过InternalParquetRecordWriter.write(row) 一行一行的写数据
public void write(T value) throws IOException, InterruptedException {
writeSupport.write(value);
++ recordCount;
checkBlockSizeReached();
}
然后在内部每行立既被分成列,列值被添加到每列的单独内存列存储中。每列的最小/最大值统计信息以及 NULL 值的数量会立即更新,所有操作都更新在内存中。详见:GroupWriter.writeGroup(group, type)
private void writeGroup(Group group, GroupType type) {
int fieldCount = type.getFieldCount();
for (int field = 0; field < fieldCount; ++field) {
int valueCount = group.getFieldRepetitionCount(field);
if (valueCount > 0) {
Type fieldType = type.getType(field);
String fieldName = fieldType.getName();
recordConsumer.startField(fieldName, field);
for (int index = 0; index < valueCount; ++index) {
if (fieldType.isPrimitive()) {
group.writeValue(field, index, recordConsumer);
} else {
recordConsumer.startGroup();
writeGroup(group.getGroup(field, index), fieldType.asGroupType());
recordConsumer.endGroup();
}
}
recordConsumer.endField(fieldName, field);
}
}
}
页面压缩
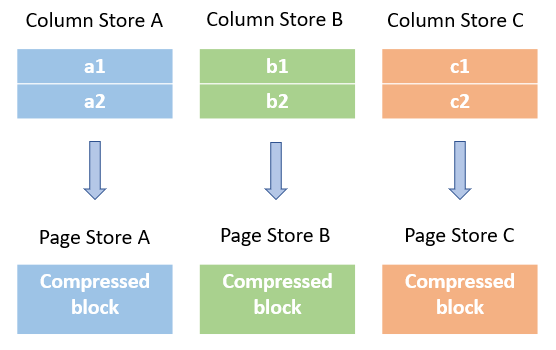
每写入一行数据都进行检查ColumnWriteStoreBase.endRecord(),判断是否已经将前100行写入内存,然后检查每列未压缩所占内存大小,如果超过了页面大小(默认1M),则压缩列内容并刷新到列的页面存储中。
@Override
public void endRecord() {
++rowCount;
// 检查写入行数是否超过行数检查阀值,第一次默认100行。这个阀值会根据实际列大小不断调整
if (rowCount >= rowCountForNextSizeCheck) {
sizeCheck();
}
}
private void sizeCheck() {
long minRecordToWait = Long.MAX_VALUE;
int pageRowCountLimit = props.getPageRowCountLimit();
long rowCountForNextRowCountCheck = rowCount + pageRowCountLimit;
for (ColumnWriterBase writer : columns.values()) {
long usedMem = writer.getCurrentPageBufferedSize();
long rows = rowCount - writer.getRowsWrittenSoFar();
// 默认1M内存减去使用内存,得到剩余内存
long remainingMem = props.getPageSizeThreshold() - usedMem;
// 剩余内存小于等于‘默认1M内存的10%’或者行数大于默认20000行
if (remainingMem <= thresholdTolerance || rows >= pageRowCountLimit) {
// 压缩列内容
writer.writePage();
remainingMem = props.getPageSizeThreshold();
} else {
// 如果未超过,设置下一次行数检查阀值
rowCountForNextRowCountCheck = min(rowCountForNextRowCountCheck, writer.getRowsWrittenSoFar() + pageRowCountLimit);
}
long rowsToFillPage =
usedMem == 0 ?
props.getMaxRowCountForPageSizeCheck()
: (long) rows / usedMem * remainingMem;
if (rowsToFillPage < minRecordToWait) {
minRecordToWait = rowsToFillPage;
}
}
if (minRecordToWait == Long.MAX_VALUE) {
minRecordToWait = props.getMinRowCountForPageSizeCheck();
}
if (props.estimateNextSizeCheck()) {
// will check again halfway if between min and max
rowCountForNextSizeCheck = rowCount +
min(
max(minRecordToWait / 2, props.getMinRowCountForPageSizeCheck()),
props.getMaxRowCountForPageSizeCheck());
} else {
rowCountForNextSizeCheck = rowCount + props.getMinRowCountForPageSizeCheck();
}
// Do the check earlier if required to keep the row count limit
if (rowCountForNextRowCountCheck < rowCountForNextSizeCheck) {
rowCountForNextSizeCheck = rowCountForNextRowCountCheck;
}
}
每个页面都包含元数据(页眉),其中包括未压缩大小、压缩大小、值的数量和统计信息:此页面中列的最小值和最大值以及 NULL 值的数量。所有数据目前都还在内存中,但与 Column store 不同的是,数据现在被压了。ColumnChunkPageWriteStore.writePage(bytes, valueCount, rowCount, statistics, rlEncoding, dlEncoding,valuesEncoding)
public void writePage(BytesInput bytes,
int valueCount,
int rowCount,
Statistics statistics,
Encoding rlEncoding,
Encoding dlEncoding,
Encoding valuesEncoding) throws IOException {
pageOrdinal++;
long uncompressedSize = bytes.size();
if (uncompressedSize > Integer.MAX_VALUE) {
throw new ParquetEncodingException(
"Cannot write page larger than Integer.MAX_VALUE bytes: " +
uncompressedSize);
}
BytesInput compressedBytes = compressor.compress(bytes);
if (null != pageBlockEncryptor) {
AesCipher.quickUpdatePageAAD(dataPageAAD, pageOrdinal);
compressedBytes = BytesInput.from(pageBlockEncryptor.encrypt(compressedBytes.toByteArray(), dataPageAAD));
}
long compressedSize = compressedBytes.size();
if (compressedSize > Integer.MAX_VALUE) {
throw new ParquetEncodingException(
"Cannot write compressed page larger than Integer.MAX_VALUE bytes: "
+ compressedSize);
}
tempOutputStream.reset();
if (null != headerBlockEncryptor) {
AesCipher.quickUpdatePageAAD(dataPageHeaderAAD, pageOrdinal);
}
if (pageWriteChecksumEnabled) {
crc.reset();
crc.update(compressedBytes.toByteArray());
parquetMetadataConverter.writeDataPageV1Header(
(int)uncompressedSize,
(int)compressedSize,
valueCount,
rlEncoding,
dlEncoding,
valuesEncoding,
(int) crc.getValue(),
tempOutputStream,
headerBlockEncryptor,
dataPageHeaderAAD);
} else {
parquetMetadataConverter.writeDataPageV1Header(
(int)uncompressedSize,
(int)compressedSize,
valueCount,
rlEncoding,
dlEncoding,
valuesEncoding,
tempOutputStream,
headerBlockEncryptor,
dataPageHeaderAAD);
}
this.uncompressedLength += uncompressedSize;
this.compressedLength += compressedSize;
this.totalValueCount += valueCount;
this.pageCount += 1;
// Copying the statistics if it is not initialized yet so we have the correct typed one
if (totalStatistics == null) {
totalStatistics = statistics.copy();
} else {
totalStatistics.mergeStatistics(statistics);
}
columnIndexBuilder.add(statistics);
offsetIndexBuilder.add(toIntWithCheck(tempOutputStream.size() + compressedSize), rowCount);
// by concatenating before collecting instead of collecting twice,
// we only allocate one buffer to copy into instead of multiple.
buf.collect(BytesInput.concat(BytesInput.from(tempOutputStream), compressedBytes));
rlEncodings.add(rlEncoding);
dlEncodings.add(dlEncoding);
dataEncodings.add(valuesEncoding);
}
写磁盘
每次写入都进行检查InternalParquetRecordWriter.checkBlockSizeReached(),判断是否已经将前100行写入内存,然后检查数据大小是否超过 Parquet 文件的指定行组大小(块大小,默认为 128 MB)。此大小包含列存储中数据未压缩大小(尚未刷新到页面存储)以及已在页面存储中已经压缩的页面存储。
private void checkBlockSizeReached() throws IOException {
// 检查写入行数是否超过行数检查阀值,第一次默认100行。这个阀值会根据实际列大小不断调整
if (recordCount >= recordCountForNextMemCheck) { // checking the memory size is relatively expensive, so let's not do it for every record.
long memSize = columnStore.getBufferedSize();
long recordSize = memSize / recordCount;
// 一般比行组大小稍小点,避免大于行组大小
if (memSize > (nextRowGroupSize - 2 * recordSize)) {
LOG.debug("mem size {} > {}: flushing {} records to disk.", memSize, nextRowGroupSize, recordCount);
flushRowGroupToStore();
initStore();
recordCountForNextMemCheck = min(max(props.getMinRowCountForPageSizeCheck(), recordCount / 2),
props.getMaxRowCountForPageSizeCheck());
this.lastRowGroupEndPos = parquetFileWriter.getPos();
} else {
// 阀值动态判断
recordCountForNextMemCheck = min(
max(props.getMinRowCountForPageSizeCheck(),
(recordCount + (long)(nextRowGroupSize / ((float)recordSize))) / 2), // will check halfway
recordCount + props.getMaxRowCountForPageSizeCheck() // will not look more than max records ahead
);
LOG.debug("Checked mem at {} will check again at: {}", recordCount, recordCountForNextMemCheck);
}
}
}
如果数据大小超过指定的行组大小,Parquet writer 会将每一列的 Column store 的内容刷新到 Pagestores 中,然后将所有 Pages store 的内容逐列刷新到输出流中。

private void flushRowGroupToStore()
throws IOException {
recordConsumer.flush();
LOG.debug("Flushing mem columnStore to file. allocated memory: {}", columnStore.getAllocatedSize());
if (columnStore.getAllocatedSize() > (3 * rowGroupSizeThreshold)) {
LOG.warn("Too much memory used: {}", columnStore.memUsageString());
}
if (recordCount > 0) {
rowGroupOrdinal++;
parquetFileWriter.startBlock(recordCount);
columnStore.flush();
pageStore.flushToFileWriter(parquetFileWriter);
recordCount = 0;
parquetFileWriter.endBlock();
this.nextRowGroupSize = Math.min(
parquetFileWriter.getNextRowGroupSize(),
rowGroupSizeThreshold);
}
columnStore = null;
pageStore = null;
}
关闭文件写入Footer
写入所有行组后,在关闭文件之前,Parquet 会将Footer添加到文件末尾。ParquetWriter.close.close()
public void close() throws IOException, InterruptedException {
if (!closed) {
// 如果行组数据未写入磁盘,关闭文件时会先把行组数据写入
flushRowGroupToStore();
FinalizedWriteContext finalWriteContext = writeSupport.finalizeWrite();
Map<String, String> finalMetadata = new HashMap<String, String>(extraMetaData);
String modelName = writeSupport.getName();
if (modelName != null) {
finalMetadata.put(ParquetWriter.OBJECT_MODEL_NAME_PROP, modelName);
}
finalMetadata.putAll(finalWriteContext.getExtraMetaData());
parquetFileWriter.end(finalMetadata);
closed = true;
}
}
Footer包括文件架构(列名及其类型)以及每个行组的详细信息(总大小、行数、最小/最大统计信息、每列的 NULL 值数)。ParquetFileWriter.end(extraMetaData)
public void end(Map<String, String> extraMetaData) throws IOException {
state = state.end();
serializeColumnIndexes(columnIndexes, blocks, out, fileEncryptor);
serializeOffsetIndexes(offsetIndexes, blocks, out, fileEncryptor);
serializeBloomFilters(bloomFilters, blocks, out, fileEncryptor);
LOG.debug("{}: end", out.getPos());
this.footer = new ParquetMetadata(new FileMetaData(schema, extraMetaData, Version.FULL_VERSION), blocks);
serializeFooter(footer, out, fileEncryptor);
out.close();
}
内容小结
行列混存非常适合快速读取数据,而且如果想进行更新或插入,它可以轻松识别记录的位置
Parquet文件时由header、data block、footer组成。其中Data block由多个行组(Row Group)组成。每个行组是按照行列混存方式存储数据,然后通过字典编码RLE/bit-packing混合编码来压缩空间。