大数据稳定性调研
背景
teddy目前使用腾讯云emr集群产品但目前存在如下问题:
- 集群稳定性差
- 机器宕机导致服务挂起问题(master母机硬件故障、core节点机器宕机)
- 机器磁盘损坏问题
- HUE问题(重启服务启动不起来,因为HUEsession刷新问题,替换过配置文件,解决后HUE启动成功,但session刷新问题依旧存在)
- tez页面访问报错500
- 自动伸缩策略异常
- spark程序经常报错连接节点失败,该节点的task任务执行失败 (应该是hdfs性能问题)
- hive一个任务会提交到yarn上2次问题
- 集群成本高
- 3月份集群总成本:124,434.82 元
- master
- core
- common
- task
- Router
- kafka成本:12,420.52元
- 收集业务日志
- dc-log-summary机器成本: 1655.47元
- Mysql成本: 235.2元
- hive元数据存储
- 其他
- filebeat采集成本
- 3月份集群总成本:124,434.82 元
现状
整体架构
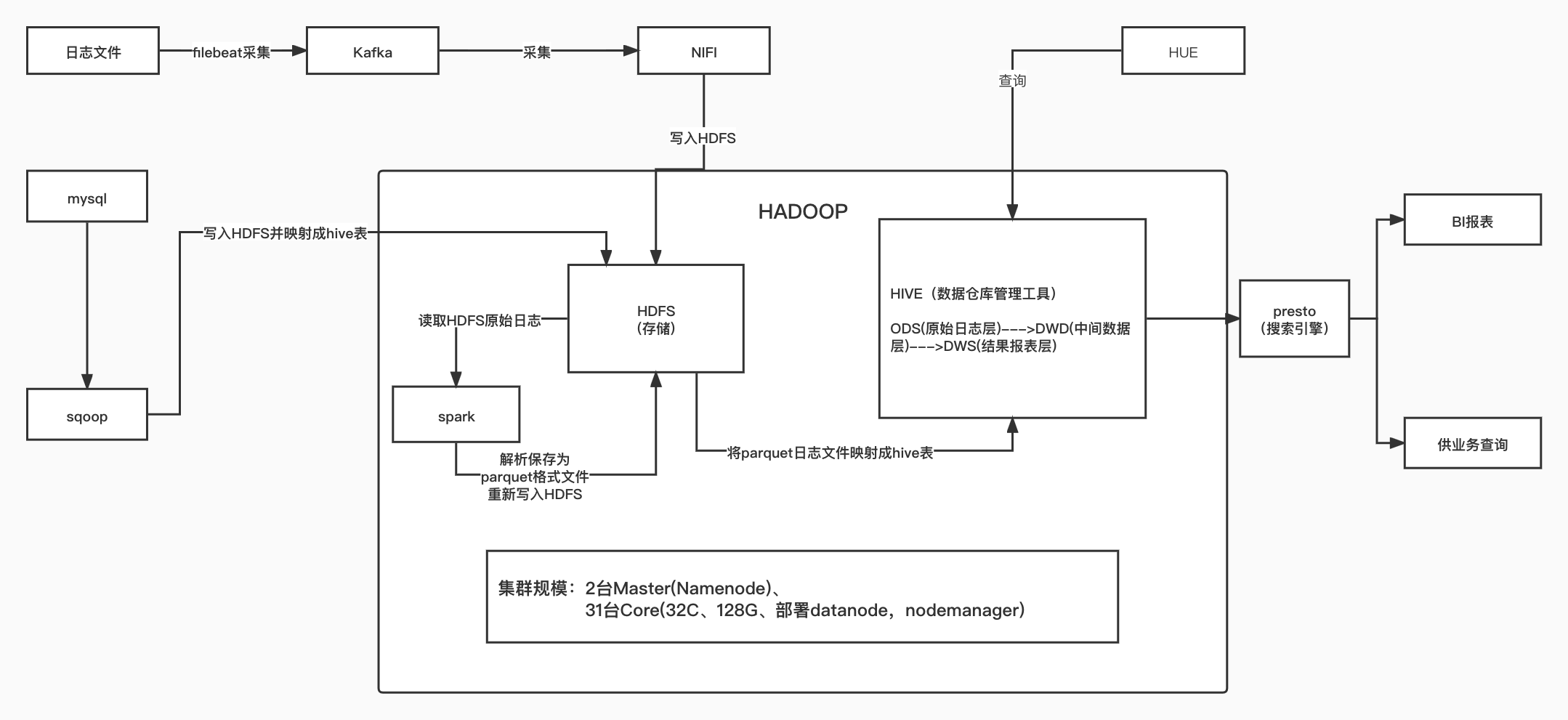
数据流转详情:
资源分布
数据分布
集群磁盘总资源:2.08PB
集群已使用磁盘:1.39PB
1. ICCC: 558TB,44.67%
(1) 号码短信Parquet: 200T,
(2) T+4短信量140T,
(3) T+1短信量20T,
(4) 雪鸮:30T,
(5) Top数据(OPPO日志):30T
2.ESP: 168TB, 16.48%
(1) dot原始日志: 20T
(2) dot的parquet:80T
(3) u3原始日志: 2T
(4) u3的Parquet: 20T
(5) 打点中间表40T
3.ECM: 30TB,3.24%
(1) 原始日志20T
(2) 商品库:6T
任务占用分布
实时任务(4个):
- 号码实时解析:固定占17%的资源
- JUMP/电商/ESP实时解析:固定占3%资源
离线任务(52个流,260个小任务):
头部任务:
- 短信量表程序(Spark)
10001__new_accurate_rt_20220406
10001__new_accurate_rt_20220409
- 短信相关统计指标计算(Hive)
10001__31-dwd_sms_funnel_req_dot_part_new_1
10001__9_dwd_sms_daily_report_imei_part_1
10001__dwd_sms_funnel_req_dot_result_new_t1_1
10001__dws_self_motion_statement_data_2
10001__dws_sms_chid_consign_t4_1
- 雪鸮(Spark):
10003__prepare-num-20220409
10003__submit_421_20220409
10003__bushu
10003__merge_20220406
10003__prepare-daily_20220409
- 号码短信用户数/Top统计(Spark):
10001__did_daily_20220409
10001__sms_num_daily_20220409
teddylogs_did_total_20220409
10001__sms_topn_20220409
10001__sign_20220409
监控任务(8个,资源占用忽略):
1.JUMP每小时探针监控
2.HTTP表数据异常性监控
3.电商BI同步MySQL监控
4.ICCC号码识别率监控
5.ESP常规指标监控
6.OPPO的Spark解析任务监控
7.OPPO数据传输到logsummary的监控
8.JUMP计费监控
使用组件
NIFI
能力
一个数据接入、处理、清洗、分发的系统,它的工作方式就是将数据看作水管中的水,它是顺着某个流程管道流动,在这中间,可以在任意节点处堵截这个“水流”,并对它进行改造,然后放回管道继续向下流去
teddy使用
Kafka --> nifi --> hdfs
当前问题
- nifi只实现数据接入和分发能力
- nifi如何保证写入文件大小和个数
- nifi是否可以支持一次性批量写入COS
- nifi是否可以支持转成parquet直接写入到COS
SparkCore
能力
Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,Spark是MapReduce的替代方案,是用来弥补基于MapReduce处理数据速度上的缺点,而且兼容HDFS、Hive,可融入Hadoop的生态系统。
teddy使用
-
spark对日志做ETL,解析成格式化的parquet
-
针对大数据量,Spark做统计聚合,比如:请求表到短信量表,雪鸮任务,号码短信TOP维度输出。
问题
- Spark提交时的参数配置,目前只能根据初步预估给出一个大体的资源分配参数,没有特定的规则(经验证,没有),因此,如何合理配置参数,最大效率的利用集群资源的问题待解。
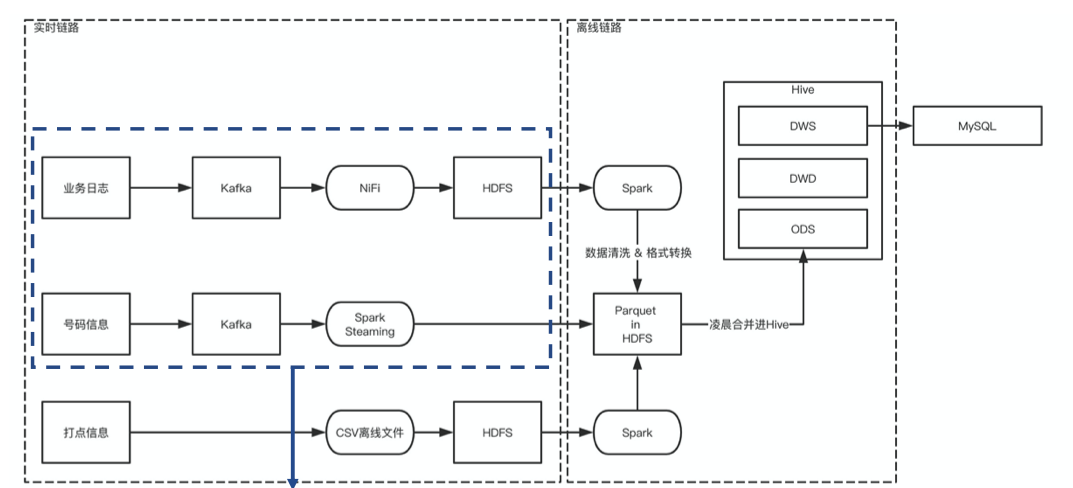
SparkStreaming
能力
Spark Streaming,用于流式数据的处理。所谓流式处理其实指的就是实时数据,之前的spark都是处理离线数据的,就是直接处理数据文件,而streaming是一直检测数据,数据出来一条,处理一条。Spark Streaming有高吞吐量和容错能力强等特点。
teddy使用
- 针对原始日志,直接从Kafka获取,ETL解析成Parquet落盘到HDFS。
问题
Hive
能力
Hive是基于Hadoop一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
teddy使用
- 常规任务Hive统计分析,出日报,周报
- 临时需求Hive统计
问题
- Hive是一个数据仓库工具,没有充分利用好这个特点,对数仓只做了简单的分层
- Hive的统计是否是最优SQL,是否有可优化空间,Hive的参数是否可继续优化,待确认。
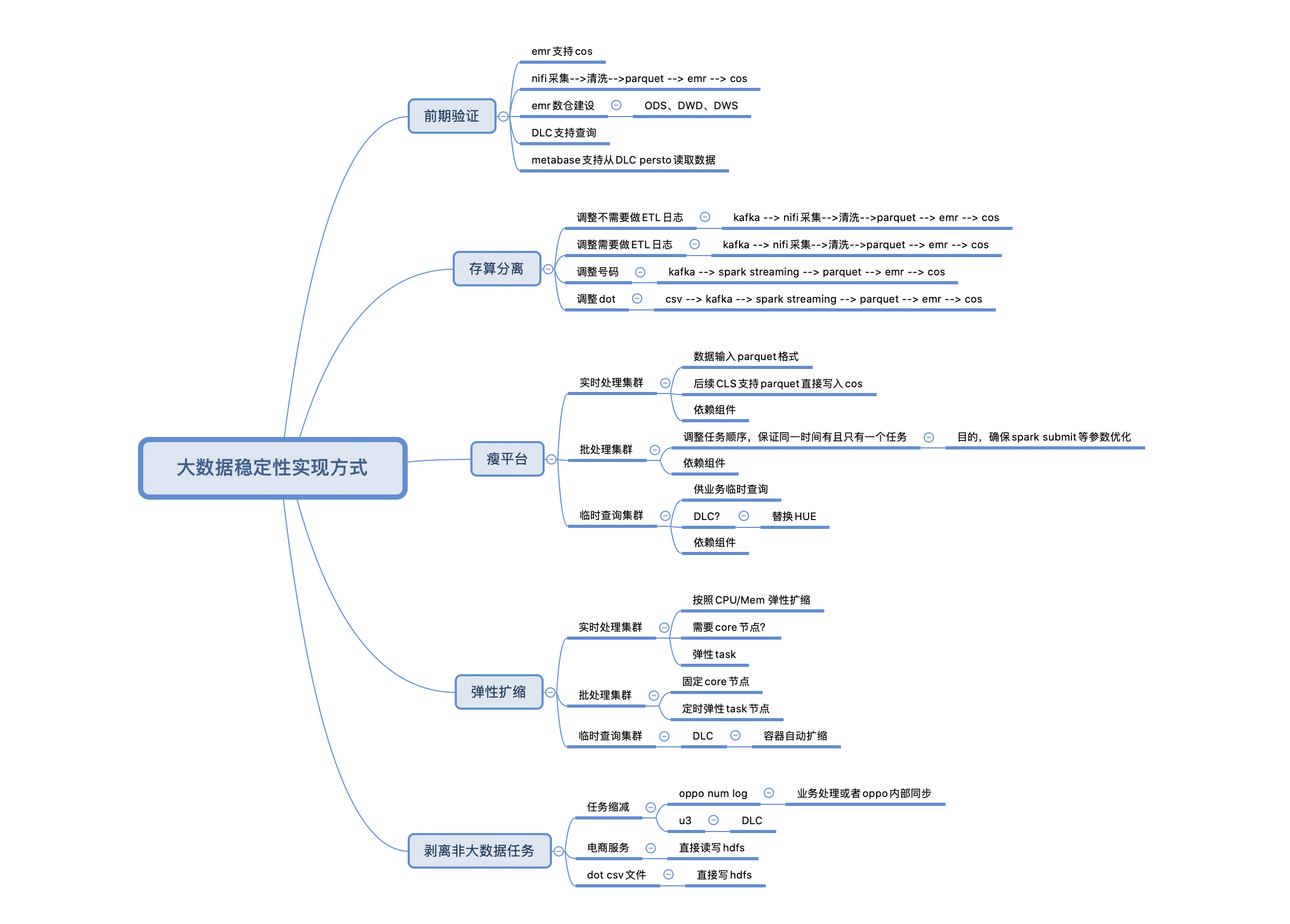
目标
- 提升稳定性
- 降低复杂度
- 合理使用资源
实施路径