Redis字符串内存计算解析
前言
Redis中Key-Value 键值对想必大家都广泛使用过,最近在使用Redis时遇到一个问题。原计划使用Redis存储用户号码数据, 键值对格式如下:<15311111111, 1>,<010-63312353, 1>。通过对应数据我们预估大约4GB左右内存使用量就可以存储6亿多条数据,而在实际使用中发现灌入8000万个号码数据,内存已经占用8G。也就是说为了存储6亿条数据,我们需要Redis规格达到64G才能满足。
看到这我们发现Key-Value 键值对在Redis中显然不是我们理解的那样存储的,那么为什么估算和真正的使用差距会这么大?现在让我们基于常用Redis4.0版,通过阅读相应的源码来了解Redis字符串内存计算逻辑。
Key/value内存分配
假设我们通过redis-cli设置key-value数据,如下所示:
redis-cli
127.0.0.1:6379> get a
(nil)
127.0.0.1:6379> set a a
OK
127.0.0.1:6379> get a
"a"
那么在redis源码中又是如何执行的呢?
-
首先,程序会调用
setCommand函数,通过解析数组argv获得索引为2的数据为value,索引为1的数据为key。调用函数tryObjectEncoding获取value的redisObject对象// t_string.c void setCommand(client *c) { ... // argv[2] 表示 Redis 客户端传递给 SET 命令的第三个参数,也就是要设置的键的值 c->argv[2] = tryObjectEncoding(c->argv[2]); setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL); } // 函数用于尝试对字符串对象进行编码优化。在 Redis 中,字符串对象的内部表示可以有不同的编码方式,例如 RAW 编码和 EMBSTR 编码。RAW 编码表示字符串对象的 ptr 指向一个 SDS(简单动态字符串)对象,而 EMBSTR 编码将字符串对象的 ptr 直接指向字符串数据,省去了额外的 SDS 结构体开销。 robj *tryObjectEncoding(robj *o) { long value; sds s = o->ptr; size_t len; ... // 检查一个字符串是否可以表示为长整型(long integer)。在 Redis 中,如果一个字符串可以被解析为长整型,那么可以将其转换为整数类型,并使用特殊的整数编码方式来存储,以节省内存和提高访问效率。 len = sdslen(s); // 如果一个字符串的长度超过20个字符,那么它不可能表示为32位或64位的整数,因此不会被尝试转换为整数类型。如果字符串长度不超过20个字符,那么它有可能表示为长整型。程序会尝试将该字符串解析为long类型整数,并检查解析是否成功。 if (len <= 20 && string2l(s,len,&value)) { ... } // 如果一个字符串很小且仍然使用原始的RAW编码方式,那么会尝试使用更高效的EMBSTR编码方式。在EMBSTR编码方式中,对象和SDS字符串会在同一块内存中分配,以节省空间并减少缓存访问带来的开销。 // #define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44 if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) { robj *emb; if (o->encoding == OBJ_ENCODING_EMBSTR) return o; emb = createEmbeddedStringObject(s,sdslen(s)); decrRefCount(o); return emb; } ... /* Return the original object. */ return o; } -
当字符串长度小于44时,将采用EMBSTR编码,也就是说会调用
createEmbeddedStringObject函数来创建redisObject对象// object.c robj *createEmbeddedStringObject(const char *ptr, size_t len) { robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); struct sdshdr8 *sh = (void*)(o+1); o->type = OBJ_STRING; o->encoding = OBJ_ENCODING_EMBSTR; o->ptr = sh+1; o->refcount = 1; o->lru = 0; sh->len = len; sh->alloc = len; sh->flags = SDS_TYPE_8; if (ptr == SDS_NOINIT) sh->buf[len] = '\0'; else if (ptr) { memcpy(sh->buf,ptr,len); sh->buf[len] = '\0'; } else { memset(sh->buf,0,len+1); } return o; }- 函数首先调用
zmalloc分配了一块内存,大小为sizeof(robj)+sizeof(struct sdshdr8)+len+1字节。其中robj是 Redis 对象的结构体,sdshdr8是简单动态字符串(SDS)的结构体。这块内存用于存储整个字符串对象的信息和字符串内容。 - 在分配的内存块中,首先存放了一个
robj结构体,然后存放了一个sdshdr8结构体。这两个结构体相邻存放,紧接着就是字符串的内容。 - 然后,函数设置字符串对象的各个属性:
type设置为OBJ_STRING表示对象类型为字符串,encoding设置为OBJ_ENCODING_EMBSTR表示对象使用 EMBSTR 编码,ptr指向存放字符串内容的地方,refcount设置为 1 表示引用计数初始化为 1,lru设置为 0 表示最近最少使用时间戳初始化为 0。 - 接下来,函数填充
sdshdr8结构体的字段:len设置为字符串的长度,alloc设置为字符串分配的内存大小(等于长度len),flags设置为SDS_TYPE_8表示 SDS 为 8 位类型。 - 最后,根据传入的
ptr和len,函数将字符串内容复制到sdshdr8结构体中的buf字段中。如果ptr为SDS_NOINIT,则会初始化buf字段为\0。如果ptr不为NULL,则会将ptr中的内容复制到buf字段,并在末尾添加\0。
- 函数首先调用
-
为了深入了解val到底占用多少内存,我们还需要知道robj和sdshdr8对应结构,相关源码如下:
// server.h #define LRU_BITS 24 typedef struct redisObject robj; struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; };这段代码定义了 Redis 对象(
redisObject)的结构体。Redis 中的数据类型都被表示为对象,包括字符串、哈希、列表等。redisObject结构体包含以下字段:type: 一个 4 位的无符号整数,用于表示对象的类型。不同的类型有不同的取值,例如 0 表示字符串类型,1 表示列表类型,2 表示哈希类型等。encoding: 一个 4 位的无符号整数,用于表示对象的编码方式。不同的编码方式用于不同类型的数据,例如字符串可以使用EMBSTR编码(小于等于 44 字节的字符串)或者RAW编码(大于 44 字节的字符串)。lru:LRU_BITS是一个宏定义,表示一个 24 位的无符号整数,lru字段用于实现 LRU(Least Recently Used)和 LFU(Least Frequently Used)算法。- 对于 LRU 算法,
lru字段存储了相对于全局lru_clock的 LRU 时间。lru_clock是一个全局的时钟,每次访问一个对象时都会更新对应对象的lru字段为当前lru_clock的值,表示该对象最近被使用过。通过比较各个对象的lru字段,可以确定最近最少使用的对象,从而实现 LRU 算法的替换策略。 - 对于 LFU 算法,
lru字段存储了 LFU 数据。具体来说,lru字段的最低 8 位表示对象的访问频率,而高 16 位表示对象的访问时间。通过比较对象的访问频率和访问时间,可以确定最少频繁使用的对象,从而实现 LFU 算法的替换策略。
- 对于 LRU 算法,
refcount: 一个整数,表示对象的引用计数。引用计数用于跟踪对象的引用情况,当对象不再被引用时,会被自动释放内存。ptr: 一个指针,指向保存对象数据的实际内存区域。具体数据的结构和内容取决于对象的类型和编码方式。
通过这个结构体,可以知道
redisObject结构体所占内存为: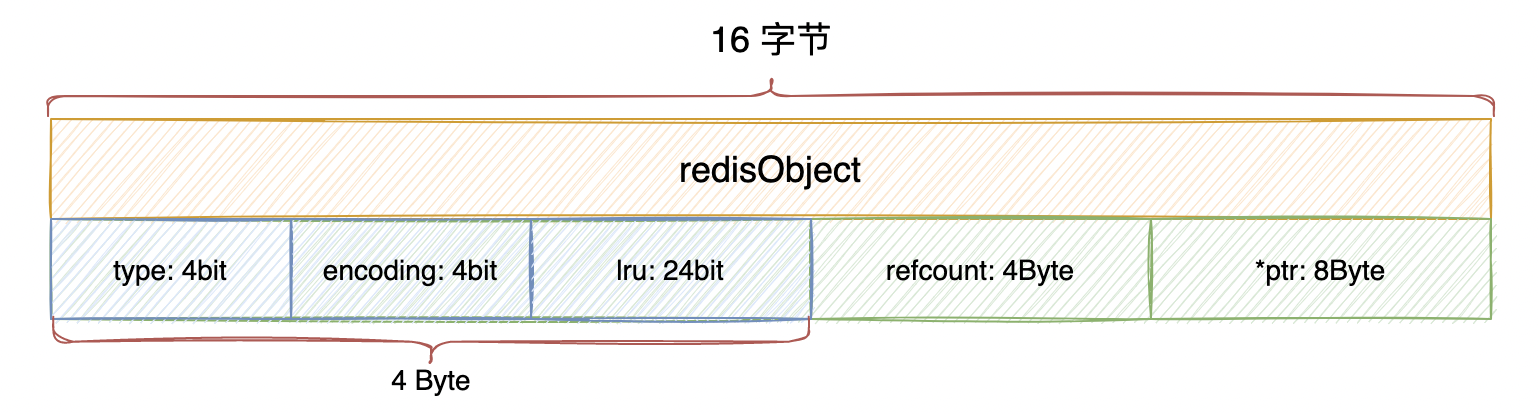
type和encoding字段各占 4 位,共占据 8 位(1 个字节)。lru字段占据 LRU_BITS 位,在默认情况下是 24 位,也就是 3 个字节。refcount字段占据 4 个字节。ptr指针字段占据 8 个字节(64 位系统上指针大小为 8 字节)。
// redis/src/sds.h struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };这是一个用于表示 Redis 中的字符串对象(
robj)的结构体sdshdr8的定义。它的字段如下:uint8_t len:使用uint8_t类型,占用 1 个字节。表示字符串的长度,用于记录当前字符串中已使用的字节数。uint8_t alloc:使用uint8_t类型,占用 1 个字节。表示为了保存字符串内容而分配的内存大小,不包括头部和空终止符的字节数。unsigned char flags:使用unsigned char类型,占用 1 个字节。其中 3 位用于表示字符串类型(type),另外 5 位当前未使用。buf:字段为一个灵活数组成员(flexible array member),,这样可以根据需要动态地保存字符串的内容。因为没有指定具体大小,所以buf字段会根据实际字符串长度进行调整。
需要注意的是,由于使用了
__attribute__((__packed__))属性,该结构体会以紧凑的方式在内存中存储,没有字节对齐。这样可以节省内存空间,但也可能会导致访问效率降低。因此,这样的结构体在一些特定场景下会更有用。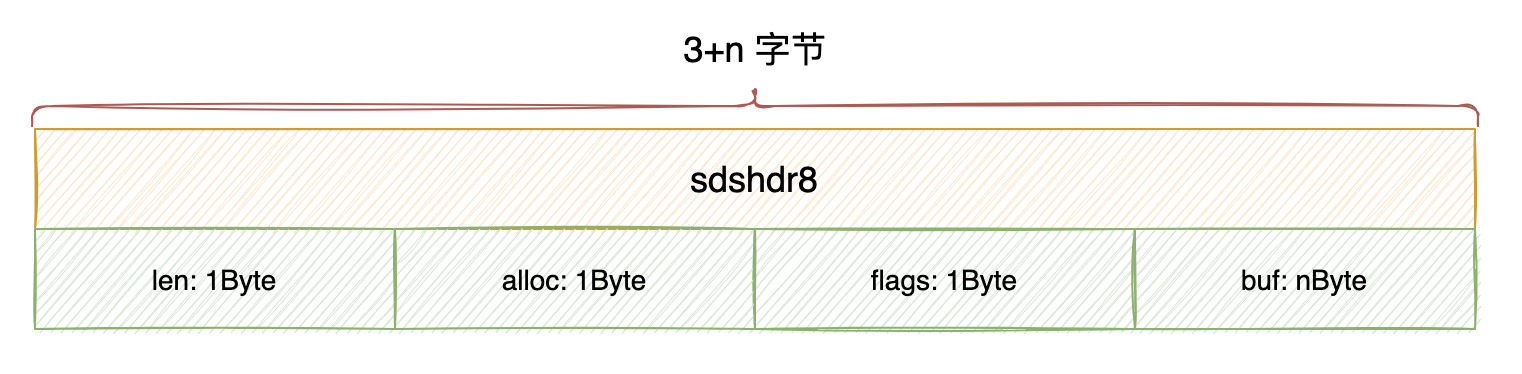
-
通过上面源码分析,我们可以知道为了构建
redisObject对象,我们需要分配多少内存robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);对应的字节长度如下:

-
掌握了value内存分配方式,我们再回头看看是如何对key进行内存分配的。上文中
setCommand函数会调用setGenericCommand函数,里面会有对key的内存分配// t_string.c void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) { ... setKey(c->db,key,val); ... } // db.c void setKey(redisDb *db, robj *key, robj *val) { if (lookupKeyWrite(db,key) == NULL) { dbAdd(db,key,val); } else { dbOverwrite(db,key,val); } ... } void dbAdd(redisDb *db, robj *key, robj *val) { // 通过 sdsdup 函数复制键对象 key 的内容到一个新的 SDS(简单动态字符串) 对象 copy 中,确保数据库中的键都是独立的字符串对象,避免共享相同的 SDS 对象,从而保证数据独立性 sds copy = sdsdup(key->ptr); // 调用 dictAdd 函数将键值对添加到数据库的字典中。字典是 Redis 中用于存储键值对的核心数据结构,dictAdd 函数会将键 copy 和值 val 添加到数据库 db->dict 所指向的字典中。如果键 copy 已经存在于字典中,添加操作会失败,返回 DICT_ERR,否则返回 DICT_OK。 int retval = dictAdd(db->dict, copy, val); ... } // sds.c // sdsup中会调用到sdsnewlen函数 sds sdsnewlen(const void *init, size_t initlen) { void *sh; sds s; char type = sdsReqType(initlen); /* Empty strings are usually created in order to append. Use type 8 * since type 5 is not good at this. */ // 如果 type 是 SDS_TYPE_5 且 initlen 为 0,那么将类型设置为 SDS_TYPE_8。这是为了处理空字符串,因为空字符串通常用于追加操作,而 SDS_TYPE_5 不适合进行追加。 if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; int hdrlen = sdsHdrSize(type); unsigned char *fp; /* flags pointer. */ sh = s_malloc(hdrlen+initlen+1); if (!init) memset(sh, 0, hdrlen+initlen+1); if (sh == NULL) return NULL; s = (char*)sh+hdrlen; fp = ((unsigned char*)s)-1; switch(type) { case SDS_TYPE_5: { *fp = type | (initlen << SDS_TYPE_BITS); break; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } } if (initlen && init) memcpy(s, init, initlen); s[initlen] = '\0'; return s; }下面对
sdsnewlen函数代码进行逐行解释:- 根据待初始化的字符串长度
initlen,确定 SDS 对象的类型type。SDS 类型是根据字符串长度来决定的,有多种类型:SDS_TYPE_5、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32 和 SDS_TYPE_64,分别对应长度32、256、65536、4294967296和18446744073709551616 - 计算 SDS 对象所需的头部大小
hdrlen,头部大小根据类型type来决定。分配内存,包含 SDS 头部、字符串数据和结尾的空字符,将指针sh指向新分配的内存。如果init为 NULL,则初始化 SDS 对象的所有字节为 0。 - 根据 SDS 对象的类型
type进行不同的处理:- SDS_TYPE_5:使用类型标志和长度
initlen设置 SDS 对象的头部,将头部指针fp指向头部数据的前一个字节。 - SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64:使用不同类型的 SDS 头部结构进行初始化,包括
len(字符串长度)和alloc(当前分配的空间大小),并设置类型标志。
- SDS_TYPE_5:使用类型标志和长度
- 如果
initlen大于 0 且init不为 NULL,则将init所指向的数据复制到 SDS 对象的字符串数据区,并在字符串末尾添加空字符\0。 - 返回指向 SDS 字符串数据的指针
s,即创建的 SDS 对象。
- 根据待初始化的字符串长度
-
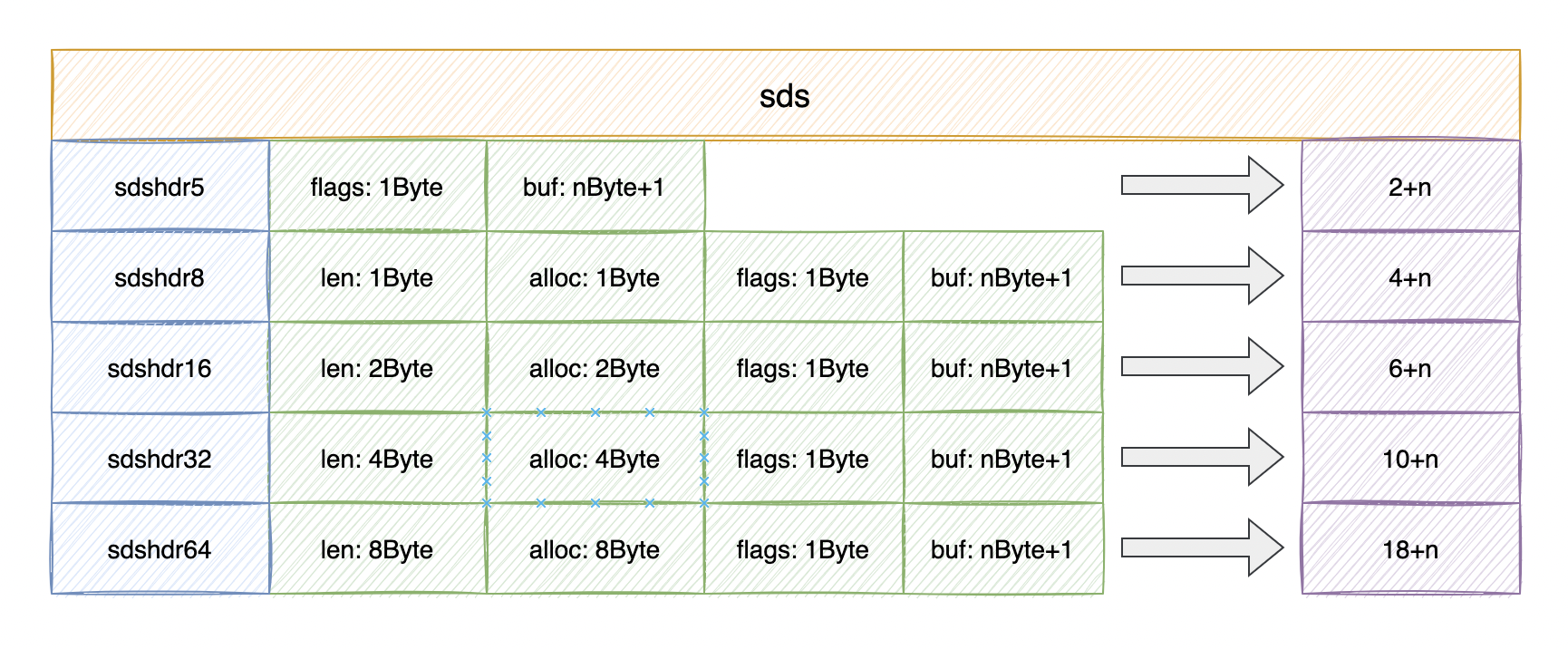
通过上面源码分析,我们知道不同长度key对应sds内存分配也不是同的,如下图所示:
-
到此我们就知道了key和val内存分配方式,那么是否我们就可以根据此方式计算内存呢,让我们通过一个redis命令来看内存占用
127.0.0.1:6379> get a "a" 127.0.0.1:6379> memory usage a (integer) 48然后我们再代入计算下:
而实际查询到内存使用为48,为何还相差24呢?让我们先跳出redis的源码分析来看看key/value存储全景图。
Key/value存储概览
在Redis 中使用哈希表(Hash Table)来实现字典(Dictionary),在存储键值对数据时,首先会对键进行哈希计算,得到一个哈希值。然后,根据这个哈希值,定位到对应的哈希槽(或称为表项、bucket),每个哈希槽都指向一个 dictEntry 结构体,这个结构体包含了键值对的信息。
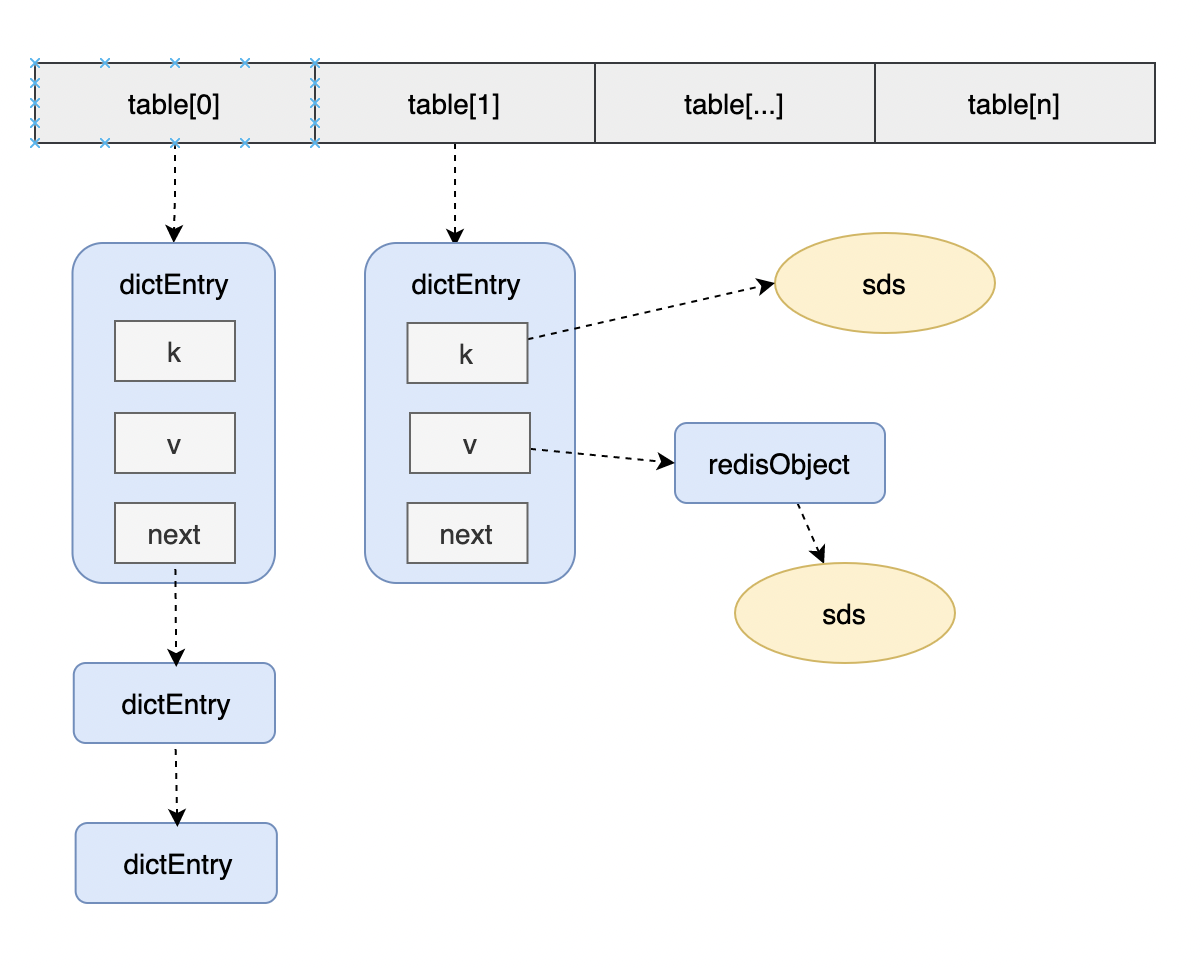
从上图,我们直观能感受到,key/value是被封装在dictEntry结构中的。这个在源码中也有体现,在源码中dbAdd函数会调用dictAdd函数:
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
这段代码是 Redis 字典(Dictionary)中的一个函数 dictAdd 的实现。函数的作用是向字典中添加一个键值对。它接受一个指向字典的指针 d,以及要添加的键 key 和对应的值 val。函数的具体实现如下:
- 首先,调用
dictAddRaw函数,尝试将键key添加到字典d中。dictAddRaw函数会返回一个指向dictEntry结构体的指针,表示成功添加或者已存在的键值对。如果添加失败(例如因为内存不足),则返回NULL。 - 接着,检查
dictAddRaw的返回值。如果返回值为NULL,说明添加键值对失败,函数直接返回DICT_ERR,表示添加失败。 - 如果
dictAddRaw的返回值不为NULL,说明添加成功或者键已经存在。然后,通过dictSetVal函数,将键对应的值设置为val。 - 最后,函数返回
DICT_OK,表示添加成功。
最后让我们看下dictEntry结构:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
dictEntry 结构体在内存中的占用空间取决于系统的架构和编译器的优化设置。一般来说,它的大小由各个字段的大小决定。假设在一个典型的 64 位系统上,void * 和 struct dictEntry * 指针的大小是 8 字节,uint64_t 和 int64_t 类型的大小也是 8 字节,double 类型的大小是 8 字节。
所以,在一个典型的 64 位系统上,dictEntry 结构体的大小为:
值得注意的是,由于 union 中的字段共用一块内存空间,实际存储的数据类型取决于在创建 dictEntry 时设置的值类型,因此 dictEntry 结构体的实际大小可能会因具体使用而有所变化。不过,大部分情况下,一个 dictEntry 结构体会占用 24 字节的内存空间。
这样,我们找到剩下24个字节是怎么回事了。接下来,让我们多通过几个例子来计算字符串内存。
字符串内存计算
用例1
127.0.0.1:6379> set redis hello
OK
127.0.0.1:6379> memory usage redis
(integer) 56
我们根据上面分析来计算内存:
用例2
127.0.0.1:6379> set 15311111111 a
OK
127.0.0.1:6379> memory usage 15311111111
(integer) 58
我们根据上面分析来计算内存:
用例3
127.0.0.1:6379> set 15311111111 1
OK
127.0.0.1:6379> memory usage 15311111111
(integer) 55
可以看到同样的key,value都为一个字符为啥获得到的长度不一致呢?我们可以通过debug查看下
127.0.0.1:6379> DEBUG OBJECT 15311111111
Value at:0x600000f3c3a0 refcount:2147483647 encoding:int serializedlength:2 lru:12202351 lru_seconds_idle:48
发现没有value:1 为int类型,占2个字节。这样我们根据上面分析得到字节数:
为什么会是int?
还记得我们前面分析
tryObjectEncoding函数吗?它会判断值是不是符合长整形,如何符合按照整形存储。
小结
经过对问题的深入探讨,我们得出以下结论:如果要存储6亿条数据,假设号码都是手机号,格式为<15311111111, 1>,那么需要约33GB的数据空间来满足需求。
然而,我们也要意识到网络上的文章可能存在版本不同或作者对某些方面未深入探究的情况,因此需要结合其他资料以及自己对源代码的阅读,来更全面地了解相关知识点。
最后,尽信书不如无书,千人千面。如果要获得更准确、全面的知识,需要持续学习、探索,并结合多方资料深入了解问题。