Redis Cluster 方案
版本
6.0
参数定义
基本
| 参数名 | 默认值 | 描述 |
|---|---|---|
| bind | 0.0.0.0 | 默认情况下,监听来自所有网络接口的连接在服务器上可用。可以只监听一个或多个接口使用“bind”配置指令,后面跟着一个or更多IP地址。 |
| port | 6379 | Redis默认监听端口 |
| tcp-backlog | 511 | backlog是tcp一个连接队列,tcp三次握手后先添加到队列中再处理 |
| daemonize | no | 默认情况下,不作为守护进程运行。如果你需要的话,用yes |
| pidfile | /var/run/redis_6379.pid | 当以daemonized运行时,redis写入一个pid文件检测进程是否存活 |
| dir | ./ | 工作目录。DB将写入到这个目录中,注意,这里必须指定目录,而不是文件名。 |
| maxmemory | 0 | Redis设置合理的maxmemory, 保证机器有20%~30%的闲置内存.默认0不限制 |
| maxmemory-policy | noeviction | 内存使用超过maxmemory后,删除过期内存策略 volatile-lru:只对设置了过期时间的key进行LRU(默认值) allkeys-lru : 删除lru算法的key volatile-random:随机删除即将过期key allkeys-random:随机删除 volatile-ttl : 删除即将过期的 noeviction : 永不过期,返回错误 |
| maxmemory-samples | 5 | Redis 的 LRU 是取出配置的数目的key,然后从中选择一个最近最不经常使用的 key 进行置换,默认的 5。如果你将 maxmemory-samples 设置为 10,那么 Redis 将会增加额外的 CPU 开销以保证接近真正的 LRU 性能 |
ACL
| 参数名 | 默认值 | 描述 |
|---|---|---|
| requirepass | 无 | client访问密码,主从下masterauth需要和requirepass保证一致 |
ACLs,也就是Access Control List,当有了ACLs之后,你就可以控制比如:
当前的用户(连接)只允许使用RPOP,LPUSH这些命令,其他命令都无法调用。
是不是很方便?来看看ACLs是怎么工作的。首先你要做的是定义用户。当登录的时候,旧版本中默认用户(defaule user)是可以做任何事的,在Redis 6.0中你可以定义默认用户:
# `setuser`...`on`表示启用此用户,off则是只定义一个不可用(unaccessable)的用户。
# `>password1 >password2 >foobar`表示设置了3个密码,可以用来做密码轮换策略。
# `+@all`表示用户可以使用所有权限,`+`后面跟命令权限如`+get`,或者`+@`后面跟某一类权限。
# `~*`表示可用(accessable)的键名,这里是`*`也就是所有键都可被访问。
127.0.0.1:6379> ACL setuser antirez on >password1 >password2 >foobar +@all ~*
# 默认用户
127.0.0.1:6379> ACL WHOAMI
"default"
# 切换用户:
127.0.0.1:6379> AUTH antirez foobar
OK
#在以前AUTH后面是直接跟密码的,现在是用户名和密码。
127.0.0.1:6379> ACL WHOAMI
"antirez"
# 因为之前给这个用户设置的是所有命令可用+所有键可见,所以现在跟default用户没有什么区别:
127.0.0.1:6379> GET foo
(nil)
127.0.0.1:6379> SET foo bar
OK
# 现在去掉一些权限:
127.0.0.1:6379> ACL setuser antirez -SET
# 把这个用户的SET权限去掉后,就不能进行这个操作了:
127.0.0.1:6379> GET foo
"bar"
127.0.0.1:6379> SET foo 123
(error) NOPERM this user has no permissions to run the 'set' command or its subcommand
# 再来查看一下现在的ACL list:
127.0.0.1:6379> ACL list
1) "user antirez on >password1 >password2 >foobar ~* +@all -set"
2) "user default on nopass ~* +@all"
**更多信息,详见:**https://redis.io/topics/acl
Clients
| 参数名 | 默认值 | 描述 |
|---|---|---|
| maxclients | 10000 | 最大连接客户端 |
| timeout | 0 | 客户端闲置多少秒后,断开连接(单位:秒) |
| tcp-keepalive | 300 | 检测TCP连接活性的周期(单位:秒) |
| client-output-buffer-limit | client-output-buffer-limit normal 0 0 0 client-output-buffer-limit replica 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 |
客户端输出缓冲区限制 适当增大slave的输出缓冲区的, 如果master节点写入较大, slave客户端的输出缓冲区可能会比较大, 一旦slave客户端连接因为输出缓冲区溢出被kill, 会造成复制重连(主从全量同步) |
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程, 触发RDB持久化过程分为手动触发和自动触发
| 参数名 | 默认值 | 描述 |
|---|---|---|
| save | save 900 1 save 300 10 save 60 10000 |
表示m秒内数据集存在n次修改时, 自动触发bgsave 1.如果从节点执行全量复制操作, 主节点自动执行bgsave生成RDB文件并发送给从节点 2. 执行debug reload命令重新加载redis,也会自动触发save操作 |
| stop-writes-on-bgsave-error | yes | 后台存储发生错误时禁止写入,默认为yes |
| rdbcompression | yes | Redis默认采用LZF算法对生成的RDB文件做压缩处理, 压缩后的文件远远小于内存大小, 默认开启。虽然压缩RDB会消耗CPU, 但可大幅降低文件的体积, 方便保存到硬盘或通过网络发送给从节点, 因此线上建议开启 |
| rdbchecksum | yes | 对rdb数据进行校验,耗费CPU资源,默认为yes |
| rdb-del-sync-files | no | |
| dbfilename | dump.rdb | rdb保存文件名 |
AOF
| 参数名 | 默认值 | 描述 |
|---|---|---|
| appendonly | no | 开启AOF功能 |
| appendfilename | appendonly.aof | AOF保存文件名,保存路径通过dir配置指定 |
| appendfsync | everysec | 命令写入aof_buf后调用系统write操作,write完成后线程返回。fsync同步文件操作由专门线程每秒调用一次 ·配置为always时, 每次写入都要同步AOF文件, 在一般的SATA硬盘 上, Redis只能支持大约几百TPS写入, 显然跟Redis高性能特性背道而驰, 不建议配置。 330 ·配置为no, 由于操作系统每次同步AOF文件的周期不可控, 而且会加 大每次同步硬盘的数据量, 虽然提升了性能, 但数据安全性无法保证。 ·配置为everysec, 是建议的同步策略, 也是默认配置, 做到兼顾性能和 数据安全性。 理论上只有在系统突然宕机的情况下丢失1秒的数据 |
| no-appendfsync-on-rewrite | no | AOF重写时会消耗大量硬盘IO, 可以开启配置no-appendfsync-onrewrite, 默认关闭。 表示在AOF重写期间不做fsync操作,配置no-appendfsync-on-rewrite=yes时, 在极端情况下可能丢失整个AOF重写期间的数据 |
| auto-aof-rewrite-percentage | 100 | 代表当前AOF文件空间( aof_current_size) 和上一次重写后AOF文件空间( aof_base_size) 的比值 |
| auto-aof-rewrite-min-size | 64mb | 表示运行AOF重写时文件最小体积, 默认为64MB 自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&( aof_current_size-aof_base_size) /aof_base_size>=auto-aof-rewritepercentage |
| aof-load-truncated | yes | 加载AOF文件时,是否忽略AOF文件不完整的情况,让Redis正常启动 |
| aof-use-rdb-preamble | yes | RDB-AOF混合持久化,需要开启appendonly。 通过AOF重写操作创建出一个同时包含RDB数据和AOF数据的AOF 文件 其中RDB数据位于AOF文件的开头 它们储存了服务器开始执行重写操作时的数据库状态 至于那些在重写操作执行之后执行的Redis命令 则会继续以AOF格式追加到AOF文件的末尾 也就是RDB数据之后 |
Replication
| 参数名 | 默认值 | 描述 |
|---|---|---|
| replicaof | replicaof |
指定当前从节点复制哪个主节点。 |
| masterauth | 空 | 从节点连接主节点需要密码 |
| masteruser | 空 | 默认用户无法运行PSYNC/复制等所需命令。这种情况下最好配置一个特殊用户与复制一起使用 |
| replica-serve-stale-data | yes | 当从节点与主节点连接中断时,如果此参数设置为“yes”,从节点可以继续处理客户端请求。 |
| replica-read-only | yes | 从节点是否开启只读模式 |
| repl-diskless-sync | no | 是否开启无盘复制 |
| repl-diskless-sync-delay | 5 | 开启无盘复制后,需要延迟多少秒后进行创建RDB操作,一般用于同时加入多个从节点时,保证多个从节点可以共享RDB |
| repl-diskless-load | disabled | slave可以直接从复制socket中加载RDB数据或者将RDB存储到一个文件中,并在文件完成后读取该文件 在许多情况下,磁盘比网络慢,存储和加载速度也慢。直接从套接字解析RDB文件意味着我们在接收到完整RDB文件前刷新当前数据库内容。因此,我们有以下选择: disabled: 不要使用无磁盘加载(先将rdb文件存储到磁盘) on-empty-db: 只有在完全安全的情况下才使用无磁盘加载 swapdb: 解析时在RAM中保留当前db内容的副本直接从套接字获取数据。注意,这需要足够的内存,如果你没有内存,你将面临OOM被杀死的风险 |
| repl-ping-replica-period | 10 | RDB文件可能会增加复制时间主节点定期向从节点发送ping命令的周期,用于判定从节点是否存活。(单位:秒) |
| repl-timeout | 60 | 从服务与主服务,ACK PING超时时间 |
| repl-disable-tcp-nodelay | no | 在slave和master同步后(发送psync/sync),后续的同步是否设置成TCP_NODELAY假如设置成yes,则redis会合并小的TCP包从而节省带宽,但会增加同步延迟,造成master与slave数据不一致假如设置成no,则redis master会立即发送同步数据,没有延迟 |
| repl-backlog-size | 1mb | 复制积压缓冲区大小 |
| repl-backlog-ttl | 3600 | 主节点在没有从节点的情况下多长时间后释放复制积压缓存区空间 |
Cluster
| 参数名 | 默认值 | 描述 |
|---|---|---|
| cluster-enabled | no | 是否开启集群模式 |
| cluster-config-file | nodes-6379.conf | 集群配置文件名称 |
| cluster-node-timeout | 15000 | 集群节点超时时间(单位:毫秒) |
| cluster-replica-validity-factor | 10 | 从节点用于故障转移资格的有效因子。默认为10 |
| cluster-migration-barrier | 1 | 主从节点切换需要的从节点数最小个数 |
| cluster-require-full-coverage | yes | Redis Cluster 可以为每个主节点设置若干个从节点,单主节点故障时,集群会自动将其中某个从节点提升为主节点。如果某个主节点没有从节点或者从节点不可用,那么当它发生故障时,从故障发现到自动完成转移集群将完全处于不可用状态。 cluster-require-full-coverage配置为no当主节点故障时只影响它负责槽的相关命令执行, 不会影响其他主节点的可用性 |
| cluster-replica-no-failover | no | 控制 master 发生故障时是否自动进行 failover。当设置为 yes 后 master 发生故障时不会自动进行 failover,这时你可以进行手动的 failover 操作 |
| cluster-allow-reads-when-down | no | 如果将其设置为no(默认情况下为默认值),则当Redis群集被标记为失败或节点无法到达时,该节点将停止为所有流量提供服务达不到法定人数或完全覆盖。这样可以防止从不知道群集更改的节点读取可能不一致的数据。可以将此选项设置为yes,以允许在失败状态期间从节点进行读取,这对于希望优先考虑读取可用性但仍希望防止写入不一致的应用程序很有用。当仅使用一个或两个分片的Redis Cluster时,也可以使用它,因为它允许节点在主服务器发生故障但无法进行自动故障转移时继续为写入提供服务。 |
Thread
| 参数名 | 默认值 | 描述 |
|---|---|---|
| io-threads-do-reads | no | 开启多线程 |
| io-threads | 4 | 拥有至少4个或者更多核启用,至少留下一个备用核,使用超过8个线程可能帮助不大。建议只有确实存在性能问题,才开启多线程 4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为 6 个线程,线程数一定要小于机器核数 |
持久化
RDB
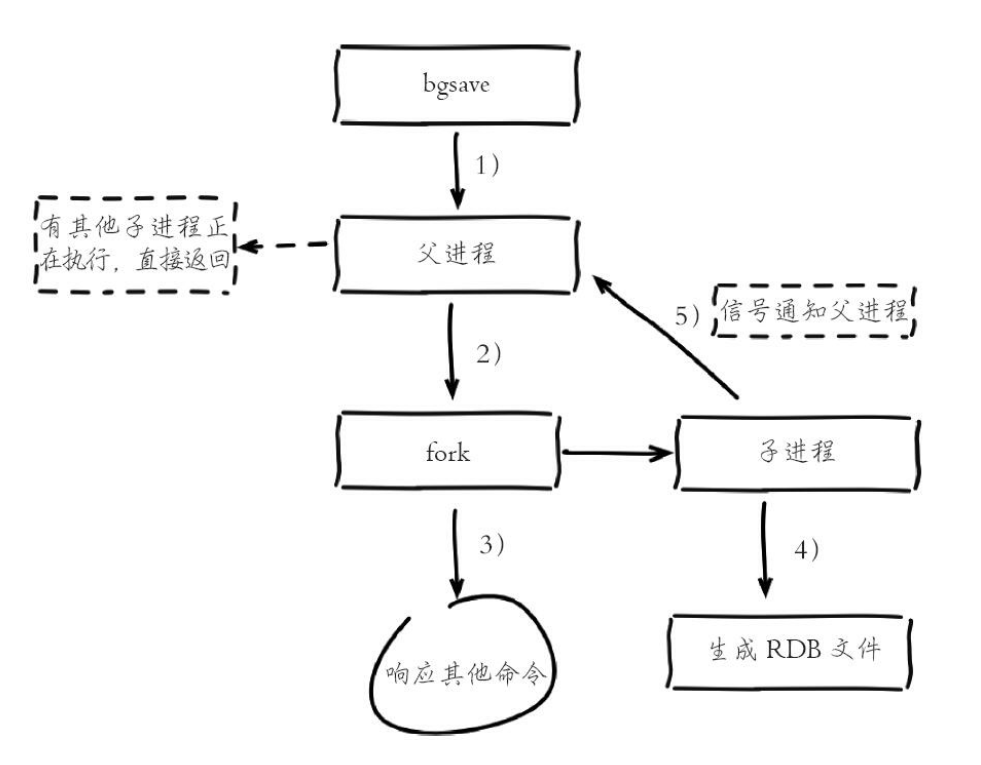
AOF
工作流程
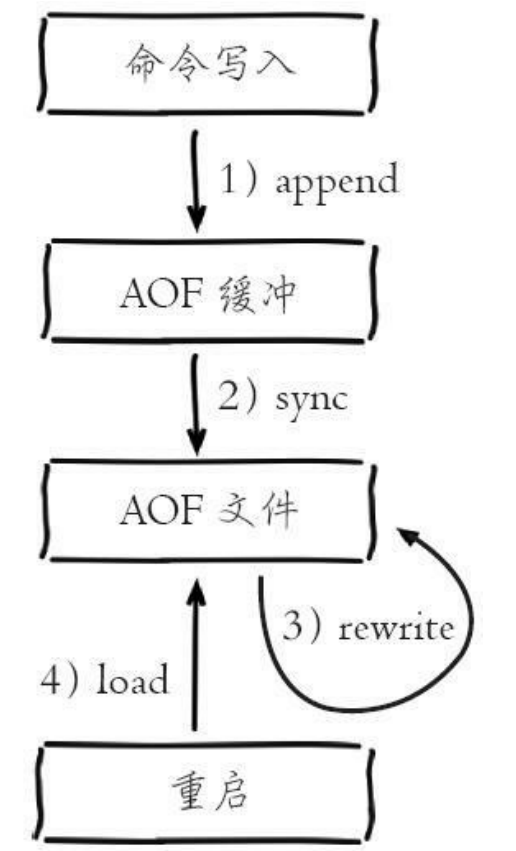
流程解析说明如下:
①、所有的写入命令会追加到 aof_buf(缓冲区)中。
②、AOF 缓冲区根据对应的策略向硬盘做同步操作。
③、随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
④、当 Redis 服务器重启时,可以加载 AOF 文件进行数据恢复。
压缩
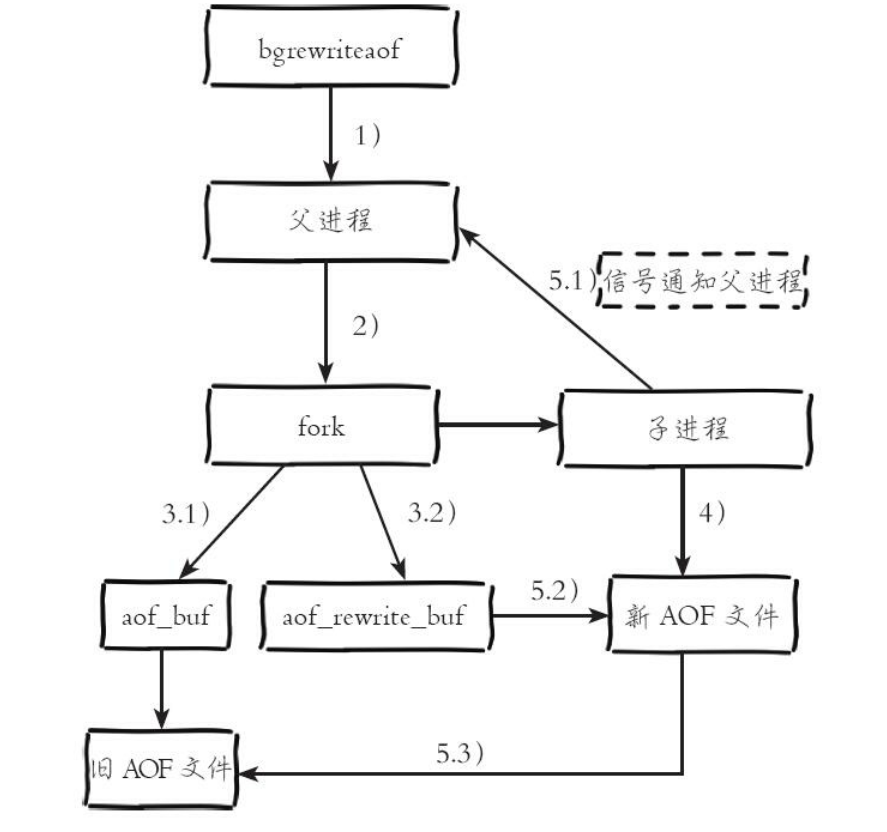
RDB-AOF
需要4.0以上版本
aof-use-rdb-preamble 选项的值设置为真。
通过AOF重写操作创建出一个同时包含RDB数据和AOF数据的AOF 文件 其中RDB数据位于AOF文件的开头 它们储存了服务器开始执行重写操作时的数据库状态 至于那些在重写操作执行之后执行的Redis命令 则会继续以AOF格式追加到AOF文件的末尾 也就是RDB数据之后
rdb以R开头,AOF以*开头
$ od -c appendonly.aof
0000000 R E D I S 0 0 0 8 372 \t r e d i s
0000020 - v e r \v 9 9 9 . 9 9 9 . 9 9 9
0000040 372 \n r e d i s - b i t s 300 @ 372 005
0000060 c t i m e 302 ~ 204 016 Z 372 \b u s e d
0000100 - m e m 302 300 z 017 \0 372 \f a o f - p
0000120 r e a m b l e 300 001 376 \0 373 002 \0 \0 002
0000140 K 1 002 V 1 \0 002 K 2 002 V 2 377 9 214 H
0000160 253 212 0 G 344 * 2 \r \n $ 6 \r \n S E L
0000200 E C T \r \n $ 1 \r \n 0 \r \n * 3 \r \n
0000220 $ 3 \r \n S E T \r \n $ 2 \r \n K 3 \r
0000240 \n $ 2 \r \n V 3 \r \n * 3 \r \n $ 3 \r
0000260 \n S E T \r \n $ 2 \r \n K 4 \r \n $ 2
0000300 \r \n V 4 \r \n
0000306
Redis恢复
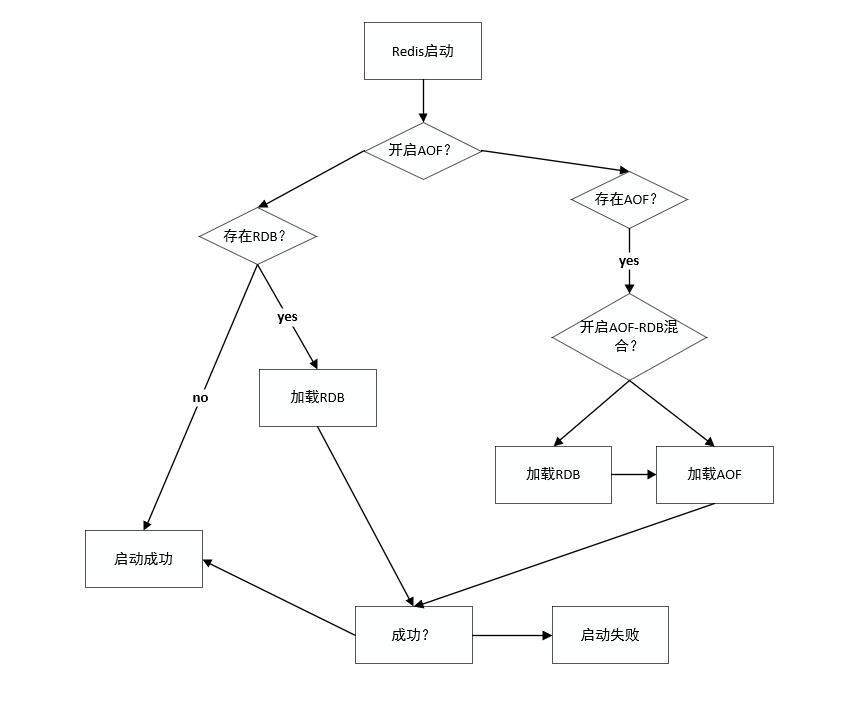
相关源码:
/* Function called at startup to load RDB or AOF file in memory. */
void loadDataFromDisk(void) {
long long start = ustime();
if (server.aof_state == AOF_ON) {
if (loadAppendOnlyFile(server.aof_filename) == C_OK)
serverLog(LL_NOTICE,"DB loaded from append only file: %.3f seconds",(float)(ustime()-start)/1000000);
} else {
rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;
errno = 0; /* Prevent a stale value from affecting error checking */
if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_NONE) == C_OK) {
serverLog(LL_NOTICE,"DB loaded from disk: %.3f seconds",
(float)(ustime()-start)/1000000);
/* Restore the replication ID / offset from the RDB file. */
if ((server.masterhost ||
(server.cluster_enabled &&
nodeIsSlave(server.cluster->myself))) &&
rsi.repl_id_is_set &&
rsi.repl_offset != -1 &&
/* Note that older implementations may save a repl_stream_db
* of -1 inside the RDB file in a wrong way, see more
* information in function rdbPopulateSaveInfo. */
rsi.repl_stream_db != -1)
{
memcpy(server.replid,rsi.repl_id,sizeof(server.replid));
server.master_repl_offset = rsi.repl_offset;
/* If we are a slave, create a cached master from this
* information, in order to allow partial resynchronizations
* with masters. */
replicationCacheMasterUsingMyself();
selectDb(server.cached_master,rsi.repl_stream_db);
}
} else if (errno != ENOENT) {
serverLog(LL_WARNING,"Fatal error loading the DB: %s. Exiting.",strerror(errno));
exit(1);
}
}
}
具体原因:
优先采用AOF,是因为AOF可以更好的保证数据不丢失
问题
当Redis做RDB或AOF重写时, 一个必不可少的操作就是执行fork操作创建子进程。fork创建的子进程不需要拷贝父进程的物理内存空间, 但是会复制父进程的空间内存页表。 例如对于10GB的Redis进程对于高流量的Redis实例OPS可达5万以上, 如果fork
操作耗时在秒级别将拖慢Redis几万条命令执行, 对线上应用延迟影响非常明显。 正常情况下fork耗时应该是每GB消耗20毫秒左右。 可以在info stats统
计中查latest_fork_usec指标获取最近一次fork操作耗时, 单位微秒 , 需要复制大约20MB的内存页表, 因此fork操作耗时跟进程总内存量息息相关
fork优化:
- 控制Redis实例最大可用内存, fork耗时跟内存量成正比, 线上建议每个Redis实例内存控制在10GB以内
- 合理配置Linux内存分配策略, 避免物理内存不足导致fork失败
- 降低fork操作的频率, 如适度放宽AOF自动触发时机, 避免不必要的全量复制等
结论
RDB-AOF方案
各云集群分析
阿里云
参数定义/差异
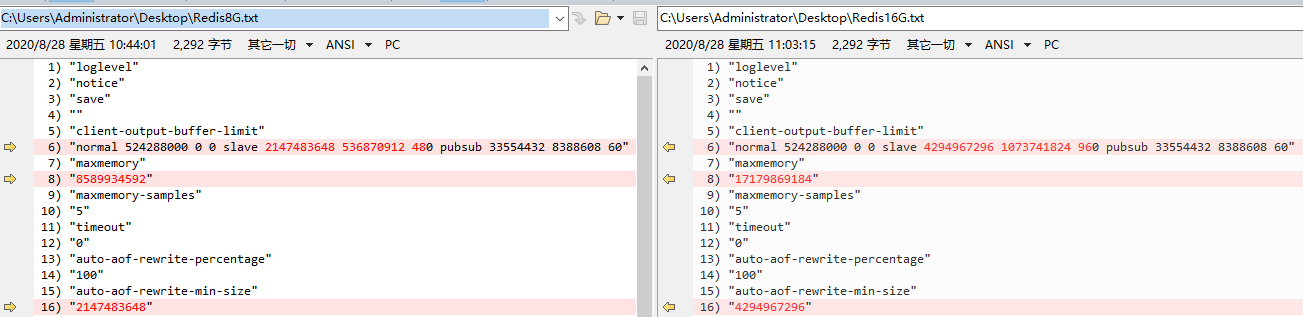
- 集群版2G、8G、16G配置基本一致,差异点如下
| 参数 | 描述 |
|---|---|
| client-out-buffer-limit | 适当增大slave的输出缓冲区的, 如果master节点写入较大, slave客户端的输出缓冲区可能会比较大, 一旦slave客户端连接因为输出缓冲区溢出被kill, 会造成复制重连 |
| maxmemory | redis可用最大物理内存。阿里云设置大于物理内存。通过设置maxmemory-policy=volatile-lru,根据LRU算法生成的过期时间来删除部分key,释放空间。如果set时候没有加上过期时间就会导致数据写满maxmemory |
| auto-aof-rewrite-min-size | 表示运行AOF重写时文件最小体积, 默认为64MB 自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&( aof_current_size-aof_base_size) /aof_base_size>=auto-aof-rewritepercentage |
-
持久化方案:阿里云采样aof机制,查看集群版、主从版配置未发现使用aof-rdb混合机制
-
阿里云有定时备份机制,采用rdb方案
京东云
架构
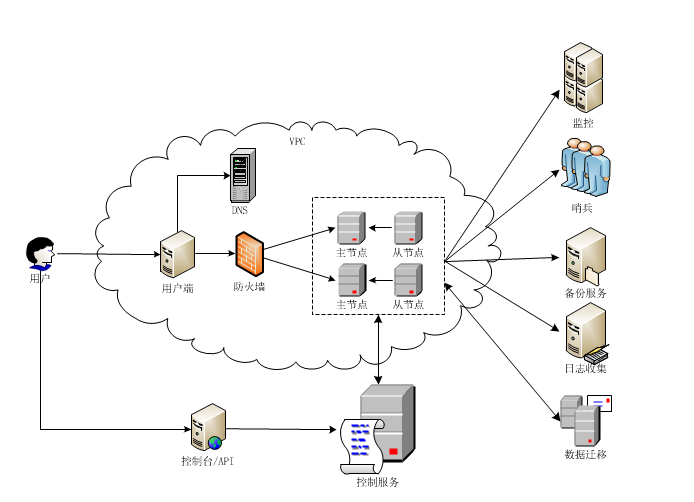
- 控制服务:处理来自用户和后端的请求任务,主要有创建、删除、查询、配置变更、failover、扩容缩容、配置修改等任务。
- 监控服务:收集Redis实例信息(资源使用和数据库键统计信息等)和物理机信息(资源使用信息和评分等),前者供用户和控制台展现,后者用于管理系统使用。
- Sentinel:哨兵监控Redis实例是否存活,多个哨兵同时工作,当发现实例down掉后,发送failover任务,自动创建新实例,并同步数据。
- 备份服务:自动定时备份,支持用户自定义备份(即将支持)。
- 日志收集:收集Redis日志信息。
- 数据迁移:数据从自建Redis到云端迁移。
参数定义/差异
| 参数 | 16G | 32G |
|---|---|---|
| repl-backlog-size | 858993459 | 1073741824 |
| maxmemory | 17179869184 | 34359738368 |
| client-output-buffer-limit | normal 0 0 0 slave 858993459 214748364 60 pubsub 134217728 33554432 60 master 0 0 0 |
normal 0 0 0 slave 1717986918 429496729 60 pubsub 134217728 33554432 60 master 0 0 0 |
腾讯云
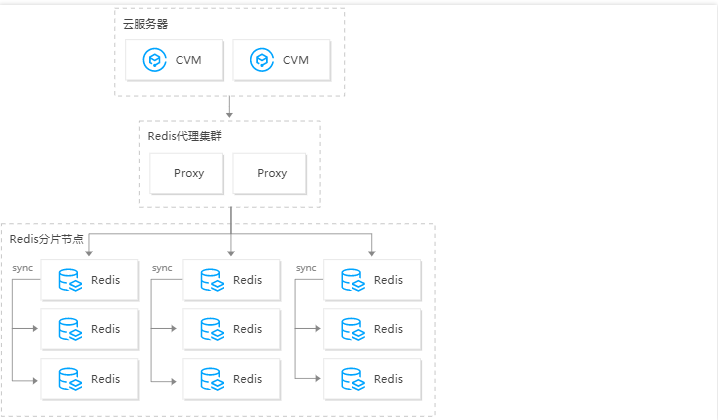
云数据库 Redis 内存版(集群架构)是腾讯云基于社区版 Redis Cluster 打造的全新版本,兼容Redis 4.0 和 Redis 5.0 版本命令,采用分布式架构,支持分片和副本的扩缩容,拥有高度的灵活性、可用性和高达千万级 QPS 的高性能。Redis 内存版(集群架构)支持3分片 - 128分片的水平方向扩展,1个 - 5个副本集的副本扩展,扩容、缩容、迁移过程业务几乎无感知,做到最大的系统可用性
参数定义/差异
| 参数 | 2G | 4G | 16G |
|---|---|---|---|
| maxmemory | 2147483648 | 4294967296 | 17179869184 |
各云特性
| 云服务 | 版本 | 特性 | 配置项 | 最大分片数 | 单分片最大容量 |
|---|---|---|---|---|---|
| 阿里云 | 标准版(主从版)client==>SLB==>redis 集群版(多分片)client==>SLB==> proxy==>redis 读写分离版client==>SLB==> proxy==>redis |
Proxy方式类似codis, 用来监控、数据分片 | 可查看 | 256 | 16G |
| 腾讯云 | 标准版 client==>Proxy==>redis 集群版client==>Proxy==>redis cluster |
Proxy提供自动分片,系统将提供数据均衡,数据迁移功能、有自定义命令 命令相对与非集群模式有一定的兼容性,主要体现在跨 Slot(槽位)数据访问 redis cluster处理真实分片 Proxy提供唯一IP地方,供client访问<br / |
可 查看 | 128 | 64G |
| 京东云 | 标准版 client==>Proxy==>redis 集群版 client==>Proxy==>redis |
Proxy类似codis.标准版和集群版主要差异,标准版无数据分片 | 可 查看 | 64 | 32G |
| AWS | ElastiCache 标准版 集群版 |
ElastiCache,支持redis和memcached。对redis部分命令有修改 | 已屏蔽 | 90,超时90需申请 | 无限制 |
各云关键参数定义(16G集群)
基本
| 参数 | 描述 | 阿里云 | 京东云 | 腾讯云 | TD |
|---|---|---|---|---|---|
| tcp-backlog | tcp三次握手后,会将接受的连接放入队列中 | 8192 | 511 | 511 | 4096 |
| maxmemory | Redis设置合理的maxmemory, 保证机器有20%~30%的闲置内存.默认0不限制 | 17179869184 | 17179869184 | 17179869184 | 15032385536 |
| maxmemory-policy | 内存使用超过maxmemory后,删除过期内存策略 volatile-lru:只对设置了过期时间的key进行LRU(默认值) allkeys-lru : 删除lru算法的key volatile-random:随机删除即将过期key allkeys-random:随机删除 volatile-ttl : 删除即将过期的 noeviction : 永不过期,返回错误 |
volatile-lru | volatile-lru | noeviction | volatile-lru |
| maxmemory-samples | Redis 的 LRU 是取出配置的数目的key,然后从中选择一个最近最不经常使用的 key 进行置换,默认的 5。如果你将 maxmemory-samples 设置为 10,那么 Redis 将会增加额外的 CPU 开销以保证接近真正的 LRU 性能 |
5 | 5 | 5 | 5 |
Clients
| 参数 | 描述 | 阿里云 | 京东云 | 腾讯云 | TD |
|---|---|---|---|---|---|
| maxclients | 最大连接客户端 | 50000 | 100000 | 10000 | 65535 |
| timeout | 客户端闲置多少秒后,断开连接(单位:秒) 默认为0,主要是避免客户端在连接时出现exception,对业务造成影响 一般设置大于0,主要是避免客户端使用不当,造成没有及时释放连接,导致redis连接占用过多。如果设置大于0,如使用连接池,需要对空闲连接做及时处理 |
0 | 300 | 0 | 0 |
| tcp-keepalive | 检测TCP连接活性的周期(单位:秒),redis会每隔X秒对它创建的TCP连接进行活性检测,防止大量死连接占用系统资源 | 20 | 300 | 300 | 120 |
| client-output-buffer-limit | 客户端输出缓冲区限制 适当增大slave的输出缓冲区的, 如果master节点写入较大, slave客户端的输出缓冲区可能会比较大, 一旦slave客户端连接因为输出缓冲区溢出被kill, 会造成复制重连(主从全量同步) |
normal 524288000 0 0 slave 4294967296 1073741824 960 pubsub 33554432 8388608 60 |
normal 0 0 0 slave 858993459 214748364 60 pubsub 134217728 33554432 60 |
normal 0 0 0 slave 4347483648 4347483647 60 pubsub 33554432 8388608 60 |
normal 524288000 0 0 slave 4294967296 1073741824 960 pubsub 33554432 8388608 60 |
RDB
| 参数 | 阿里云 | 京东云 | 腾讯云 |
|---|---|---|---|
| save | null | null | null |
| stop-writes-on-bgsave-error | yes | yes | yes |
| rdbcompression | yes | yes | yes |
| rdbchecksum | yes | yes | yes |
| rdb-del-sync-files |
AOF
| 参数 | 描述 | 阿里云 | 京东云 | 腾讯云 | TD |
|---|---|---|---|---|---|
| appendonly | 开启AOF功能 | yes | no | no | yes |
| appendfsync | 命令写入aof_buf后调用系统write操作,write完成后线程返回。fsync同步文件操作由专门线程每秒调用一次 ·配置为always时, 每次写入都要同步AOF文件, 在一般的SATA硬盘 上, Redis只能支持大约几百TPS写入, 显然跟Redis高性能特性背道而驰, 不建议配置。 330 ·配置为no, 由于操作系统每次同步AOF文件的周期不可控, 而且会加 大每次同步硬盘的数据量, 虽然提升了性能, 但数据安全性无法保证。 ·配置为everysec, 是建议的同步策略, 也是默认配置, 做到兼顾性能和 数据安全性。 理论上只有在系统突然宕机的情况下丢失1秒的数据 |
everysec | everysec | no | everysec |
| no-appendfsync-on-rewrite | AOF重写时会消耗大量硬盘IO, 可以开启配置no-appendfsync-onrewrite, 默认关闭。 表示在AOF重写期间不做fsync操作,配置no-appendfsync-on-rewrite=yes时, 在极端情况下可能丢失整个AOF重写期间的数据 | no | yes | no | no |
| auto-aof-rewrite-min-size | 表示运行AOF重写时文件最小体积, 默认为64MB 自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&( aof_current_size-aof_base_size) /aof_base_size>=auto-aof-rewritepercentage |
4294967296 | 67108864 | 67108864 | 2147483648 |
Replication
| 参数 | 阿里云 | 京东云 | 腾讯云 | TD |
|---|---|---|---|---|
| repl-diskless-sync | no | yes | no | no |
| repl-diskless-sync-delay | 5 | 3 | 5 | 5 |
| repl-timeout | 60 | 60 | 120 | 60 |
| repl-backlog-size | 33554432 | 858993459 | 1048576 | 100m |
Cluster
阿里云、京东云非cluster方案,所以此参数无意义
| 参数 | 描述 | 默认 | 腾讯云 |
|---|---|---|---|
| cluster-migration-barrier | 主从节点切换需要的从节点数最小个数 腾讯云最大副本数:5,此处设置默认值为100.字面理解上,是无法做自己主从切换的。是否出现故障由Proxy来做主从切换不得而知。 |
1 | 100 |
| cluster-allow-reads-when-down | 如果将其设置为no(默认情况下为默认值),则当Redis群集被标记为失败或节点无法到达时,该节点将停止为所有流量提供服务达不到法定人数或完全覆盖。这样可以防止从不知道群集更改的节点读取可能不一致的数据。可以将此选项设置为yes,以允许在失败状态期间从节点进行读取,这对于希望优先考虑读取可用性但仍希望防止写入不一致的应用程序很有用。当仅使用一个或两个分片的Redis Cluster时,也可以使用它,因为它允许节点在主服务器发生故障但无法进行自动故障转移时继续为写入提供服务 | no | 无此参数 |
总结
- RDB都关闭,每日备份都是通过外部脚本在0~7之间进行自动备份
- 只有阿里云,开启AOF模式,但AOF模式非混合模式
- 只有腾讯云redis为cluster方案,但腾讯云前面又加了一层代理。主要是用来监控、集群管理、主从切换、IP地址收敛
redis最终配置
bind {{ ip }}
protected-mode yes
port 6379
tcp-backlog 4096
daemonize yes
maxmemory {{ maxmemory }}
maxmemory-policy volatile-lru
maxmemory-samples 5
supervised no
dir /data/redis/data/
pidfile /data/redis/redis_6379.pid
loglevel notice
logfile /data/redis/log/redis_6379.log
databases 16
always-show-logo yes
# ACL
requirepass {{ pass }}
# Clients
maxclients 65535
timeout 0
tcp-keepalive 120
client-output-buffer-limit normal 524288000 0 0
client-output-buffer-limit replica {{ client-output-buffer-limit }}
client-output-buffer-limit pubsub 33554432 8388608 60
# RDB
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
rdb-del-sync-files no
# Replication
masterauth {{ pass }}
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-diskless-load disabled
repl-disable-tcp-nodelay no
replica-priority 100
repl-backlog-size 100mb
repl-backlog-ttl 3600
acllog-max-len 128
lazyfree-lazy-eviction no
lazyfree-lazy-expire yes
lazyfree-lazy-server-del yes
replica-lazy-flush no
lazyfree-lazy-user-del no
# AOF
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size {{ auto-aof-rewrite-min-size }}
aof-load-truncated yes
aof-use-rdb-preamble yes
# 集群配置
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
cluster-replica-validity-factor 10
cluster-migration-barrier 1
cluster-require-full-coverage no
cluster-replica-no-failover no
cluster-allow-reads-when-down no
# slowlog
slowlog-log-slower-than 10000
slowlog-max-len 1024
# 其他
lua-time-limit 5000
latency-monitor-threshold 100
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
# 屏蔽关键命令
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG CONFIG-T
rename-command KEYS KEYS-T
操作系统选型
版本
-
**阿里云:**8.2、8.1、8.0、7.8、7.7、7.6
-
**京东云:**7.6
-
**AWS:**8.2、8.1、8.0、7.8、7.7、7.6
-
**腾讯云:**8.0、7.7、7.6
-
**百度云:**8.2、7.8、7.7、7.6
版本差异
| Feature | CentOS 7 | CentOS 8 |
|---|---|---|
| Kernel | 基于Fedora 19和上游Linux内核3.10 | 基于Fedora 28和上游Linux内核4.18(可升级Linux内核,但为了稳定性,建议仅接受系统的内核升级补丁) |
| 硬件架构 | 64-bit AMD 64-bit Intel IBM POWER7 IBM System z |
AMD and Intel 64-bit architectures The 64-bit ARM architecture IBM Power Systems, Little Endian IBM Z |
| Git | Git version 1.8 | Git version 2.18 |
| Security | 随附对OpenSSL 1.0.1和TLS 1.0的支持 | 随附对OpenSSL 1.1.1和TLS 1.3,TLS 1.0和TLS 1的支持 |
| Software Management | 使用随RPM 4.11分发的YUM v3 | YUM软件包管理器现在基于DNF技术,并且提供了对模块化内容的支持,使用随RPM 4.14分发的YUM v4 |
| httpd/Apache | HTTP Server 2.4 | HTTP Server 2.4 |
| Python | Python 2.7.5和对Python 2.7的有限支持 | Python 3.6和对Python 2.7的有限支持 |
| php, ruby, perl | PHP 5.4.16、Ruby 2.0.0、Perl 5.16.3 | PHP 7.2、Ruby 2.5、Perl 5.26 |
| Desktop Environment | 默认的GNOME Display Manager是X.Org服务器 | 默认的GNOME Display Manager是Wayland,GNOME Shell版本3.28 |
| Databases | MySQL 5.5、MariaDB 5.5、PostgreSQL 9.2 | MariaDB 10.3(参考:CentOS 8上安装MariaDB 10.3版,及保护MariaDB和连接到MariaDB Shell)、MySQL 8.0、PostgreSQL 10、PostgreSQL 9.6和Redis 5 |
| Virtualization | 使用qemu-kvm和virt-manager | 随qemu-kvm 2.12一起分发,弃用了virt-manager,由Cockpit接管 |
| Firewall | 使用iptables数据包过滤框架 | 使用nftables数据包过滤框架 |
| NTP | Chronyd与NTP两者都支持 | 只使用Chronyd,不支持NTP部署 |
| Nginx | Nginx默认情况下不可用 | CentOS 8引入了Nginx Web服务器。版本1.14 |
| Java | OpenJDK的8 | OpenJDK 11和OpenJDK 8 |
| network | 拥有TCP网络栈版本4.18,可以提供更高的性能、更好的可伸缩性和更稳定的性能。性能得到了提高,特别是在繁忙的TCP服务器与高进入连接速率 | |
| 最大文件 | 最大. (单独) 文件大小= 500TiB 最大. 文件系统大小 = 500TiB |
XFS文件系统支持的最大文件大小已从500 TiB增加到1024 TiB |
最终选型
Centos 8
需要调优参数
| 参数名 | 默认值 | 描述 |
|---|---|---|
| vm.overcommit_memory | 0 | 内存分配控制. 0: 表示内核将检查是否有足够可用内存,如果有足够可用内存,内存申请通过,否则申请失败,并把错误返回给应用程序 1:表示内核允许超量使用内存直到用完为止 |
| swappiness | 60 | swap对于操作系统来比较重要, 当物理内存不足时, 可以将一部分内页进行swap操作, 已解燃眉之急。swap空间由硬盘提供, 对于需要高并发、 高吞吐的应用来说, 磁盘IO通常会成为系统瓶颈。 在Linux中, 并不是要等到所有物理内存都使用完才会使用到swap, 系统参数swppiness会决定操作系统使用swap的倾向程度swappiness的取值范围是0~100, swappiness的值越大, 说明操作系统可能使用swap的概率越高, swappiness值越低, 表示操作系统更加倾向于使用物理内存 0:linux3.5以及以上:宁愿用swap也不用OOM Killer linux3.4以及更早:宁愿用swap也不用OOM Killer 1:linux3.5以及以上,宁愿用swap也不用OOM Killer 60:默认值 100:操作系统会主动使用swap |
| Transparent Huge Pages(THP) | Linux kernel在2.6.38内核增加了THP特性, 支持大内存页(2MB) 分配, 默认开启。 当开启时可以降低fork子进程的速度, 但fork操作之后, 每个内存页从原来4KB变为2MB, 会大幅增加重写期间父进程内存消耗。 同时每次写命令引起的复制内存页单位放大了512倍, 会拖慢写操作的执行时间, 导致大量写操作慢查询 参数设置:/etc/rc.local中追加echo never > /sys/kernel/mm/transparent_hugepage/enabled |
|
| OOM killer | OOM killer会在可用内存不足时选择性地杀掉用户进程。当oom_adj设置为最小值时, 该进程将不会被OOM killer杀掉, 设置方法如下: echo -17 > /proc/${process_id}/oom_adj |
|
| ulimit | 查看和设置系统当前用户进程的资源数。 open files: 单个用户同时打开的最大文件个数。ulimit -Sn {max-open-files} Redis建议把open files至少设置成maxclients+32. maxclients用来处理客户端连接、32是redis内部会使用最多个文件描述符 |
|
| tcp-backlog | Redis默认的tcp-backlog值为511, 可以通过修改配置tcp-backlog进行调整, 如果Linux的tcp-backlog小于Redis设置的tcp-backlog, 那么在Redis启动时会看到如下日志: # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/ net/core/somaxconn is set to the lower value of 128. **参数设置:**net.core.somaxconn = 511 |
容灾方案
需求场景
- 业务量请求量上升,原有规格不够
- 线上机器出现故障
- 双11、618等活动临时场景,短信电话等业务量提升
以上需求主要涉及到集群新建、扩容和缩容,而集群操作官方提供了有效工具redis-trib.rb,支持的操作如下:
- create:创建集群
- check:检查集群
- info:查看集群信息
- fix:修复集群
- reshard:在线迁移slot
- rebalance:平衡集群节点slot数量
- add-node:添加新节点
- del-node:删除节点
- set-timeout:设置节点的超时时间
- call:在集群所有节点上执行命令
- import:将外部redis数据导入集群
新建
扩容
缩容
监控
redis_exporter方案
https://github.com/oliver006/redis_exporter
标准化部署
需求
- 可根据不同参数,
- ip、pass等需要替换模板中配置
- 需要生成随机秘钥函数
- 区分初次安装和扩缩容
- 需要每日备份RDB文件,如果需要。需要编写相关脚本
流程
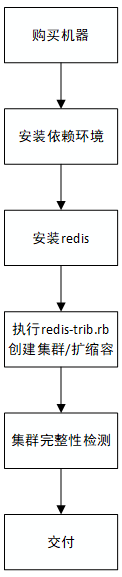
成本核算
现状
| 集群 | 机器 | 使用情况 | 机器成本 | 同等内存规格阿里云价格 |
|---|---|---|---|---|
| numredis | 8 vCPU 64 GiB 9台物理机,2节点/每机器 |
当前使用情况: CPU:2% 内存:75% 总: 576G, 可用内存288G, 32G/每主节点 |
单台:893.10 总计:7144.8 |
按照:32G/每主节点 选择256G集群版(16节点) 每秒新建连接数:50000 最大连接数:160000 最大内网带宽:1536MByte 价格:15600 |
| num-shopwhiteredis | 4 vCPU 8GiB 3台物理机,2节点/每机器 |
当前使用情况: CPU:3% 内存:30% 总: 24G 4G/每主节点 |
单台:264.55 总计:793.65 |
按照:2G/每主节点 选择24G集群版(4节点) 每秒新建连接数:40000 最大连接数:40000 最大内网带宽:384MByte 价格:1495 |
| num-custom | 2 vCPU 4GiB 3台物理机,2节点/每机器 |
当前使用情况: CPU:3% 内存:24% 总: 12G 2G/每主节点 |
单台:164.45 总计:493.35 |
按照:2G/每主节点 选择16G集群版(4节点) 每秒新建连接数:40000 最大连接数:40000 最大内网带宽:384MByte 价格:975 |
注:8 vCPU64GiB价格:923,4vCPU32GiB价格:468*2=936。价格相差:13
低规格
| 规格 | 集群版 | 主从版 | 同比单台机器ECS价格 | ECS主从搭建价格 |
|---|---|---|---|---|
| 1G | 价格:91 每秒新建连接数:20000 最大连接数:20000 最大内网带宽:48MByte |
价格:65 每秒新建连接数:10000 最大连接数:10000 最大内网带宽:10MByte |
30.55 | 61.1 |
| 2G | 价格:182 每秒新建连接数:20000 最大连接数:20000 最大内网带宽:96MByte |
价格:117 每秒新建连接数:10000 最大连接数:10000 最大内网带宽:16MByte |
123.50 | 247 |
| 4G | 价格:273 每秒新建连接数:20000 最大连接数:20000 最大内网带宽:192MByte |
价格:221 每秒新建连接数:10000 最大连接数:10000 最大内网带宽:24MByte |
141.05 | 282.1 |
| 8G | 价格:520 每秒新建连接数:40000 最大连接数:40000 最大内网带宽:192MByte |
价格:429 每秒新建连接数:10000 最大连接数:10000 最大内网带宽:24MByte |
184.60 | 369.2 |
问题
- maxmemory设置,正常情况下主从节点内存使用量趋同,只有在做全量复制会导致主节点内存升高。通常建议保证机器有20%~30%的闲置内存。分析线上numredis,某台物理机2个节点都为mater、节点已使用48G,每天bgsave时观察云监控内存无明显变化。结合内存回收策略,可能配置20%闲置(系统、redis fork)比较合理。
- 单台物理机:部署2节点或者单节点。单台2节点问题,可能会存在同一节点上2主现象。
- 标准化规格选型,按照2vCPU, 4G、6G、8G、16G
总结
- <= 8G 购买云服务更合适,小业务主从版更合适
- 8G以上自建cluster更合适
性能压测
测试环境
2vCPU, 8G内存 高效云盘 ECS 3台;
操作系统: Centos 7.6 64位
redis版本:6.0.3
1台redis服务
2台测试机
测试工具
redis-benchmark
检测指标
- 存活情况
- 连接数
- 阻塞客户端数量
- 使用内存峰值
- 内存碎片率
- 缓存命中率
- OPS
- 持久化
- 失效KEy
- 慢日志
测试结果
同等规格写入value大小
测试命令
redis-benchmark -h 192.168.8.238 -p 6379 -a tdx_rds_ts -t set,get -c 3500 -d bytes -n 25000000 -r 5000000
测试结果
| 指标 | 10字节 | 128字节 | 512字节 | 1024字节 | 2048字节 |
|---|---|---|---|---|---|
| QPS(GET) | 141,864 | 97,733 | 106,617 | 103,419 | 95,896 |
| QPS(SET) | 124,284 | 91,772 | 48,915 | 65,944 | 89,565 |
| CPU average | 57% | 68% | 89% | 88% | 54% |
| MEM average | 17% | 22% | 82% | 85% | 86% |
| DISK_wriebytes | 7.04MB/s | 31.24MB/s | 59.81MB/s | 85.64MB/s | 105.84MB/s |
| DISK_writelops | 17.25Count/s | 127.34 | 970 | 915 | 1.12k |
| 流入速率 | 118Mb/s | 187Mb/s | 383Mb/s | 739Mb/s | 1.83Gb/s |
| 流出速率 | 131Mb/s | 195Mb/s | 542Mb/s | 832Mb/s | 826Mb/s |
| TCP total | 7006 | 7008 | 7008 | 7007 | 7011 |
| Clients | 7000 | 7000 | 7000 | 7000 | 7000 |
| blocked_clients | 0 | 0 | 0 | 0 | 0 |
同等规格并发client大小
测试命令
redis-benchmark -h 192.168.8.238 -p 6379 -a tdx_rds_ts -t set,get -c client -d 128 -n 2500000 -r 500000
测试结果
| 指标 | 500 parallel | 5000 parallel | 10000 parallel | 30000 parallel | 50000 parallel |
|---|---|---|---|---|---|
| QPS(GET) | 139,150 | 114,299 | 110,795 | 104,549 | 105,821 |
| QPS(SET) | 129,282 | 86,352 | 85,750 | 83,594 | 83,620 |
容量评估/规格选型
低规格
| 功能 | 1G | 2G | 4G | 8G |
|---|---|---|---|---|
| 架构 | 主从版 | 主从版 | 主从版 | 集群版 |
| 规格 | 1主1从 | 1主1从 | 1主1从 | 4分片 |
| QPS | 10000 | 10000 | 10000 | 40000 |
| 最大连接数 | 10000 | 10000 | 10000 | 40000 |
| 多DB | 支持 | 支持 | 支持 | 支持 |
| 最大内网带宽 | 10MByte | 16MByte | 24MByte | 192MByte |
| 扩缩容支持 | 支持 | 支持 | 支持 | 支持 |
高规格
| 功能 | 18G | 30G | 42G | 54G | 70G | 98G | 126G |
|---|---|---|---|---|---|---|---|
| 物理机 | 2vCPU, 8G | 2vCPU, 8G | 2vCPU, 16G | 2vCPU, 8G | 2vCPU, 16G | 2vCPU, 16G | 2vCPU, 16G |
| 物理机数量 | 6 | 10 | 6 | 18 | 10 | 14 | 18 |
| 架构 | redis cluster6.0 | redis cluster6.0 | redis cluster6.0 | redis cluster6.0 | redis cluster6.0 | redis cluster6.0 | redis cluster6.0 |
| 规格 | 3主3从 | 5主5从 | 3主3从 | 9主9从 | 5主5从 | 7主7从 | 9主9从 |
| QPS | (8万 - 10万)/分片 | (8万 - 10万)/分片 | (8万 - 10万)/分片 | (8万 - 10万)/分片 | (8万 - 10万)/分片 | (8万 - 10万)/分片 | (8万 - 10万)/分片 |
| 最大连接数 | 50000/分片 | 50000/分片 | 50000/分片 | 50000/分片 | 50000/分片 | 50000/分片 | 50000/分片 |
| 最大内网带宽 | 6 Gbps | 10Gbps | 6 Gbps | 18Gbps | 10Gbps | 14Gbps | 18Gbps |
| 多DB | 不支持 | 不支持 | 不支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 扩缩容支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
数据迁移
redis-shake是阿里云Redis&MongoDB团队开源的用于redis数据同步的工具。
支持源redis到目的redis数据同步