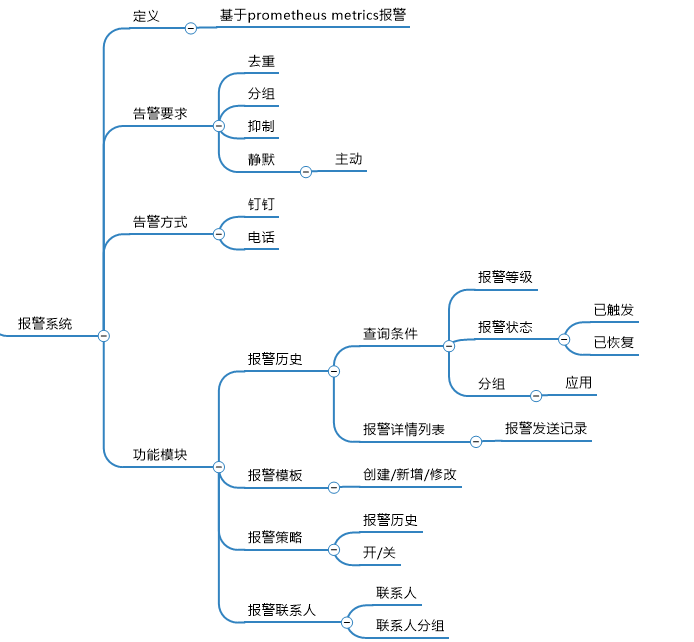
统一监控平台
背景
-
业务对服务的稳定性、可靠性要求越来越高
-
云基础设施不完善(如:京东云),多云监控部署一对一
-
监控平台建设、报警指标,报警分级,无完善规则规范
-
缺少AIOps。如:故障预测、容量预估
-
监控维度不全面,比如k8s监控
-
业务权限不足、问题排查需要登录云服务、机器、监控grafana进行数据收集及分析。目前业务无法自我排查
监控概览

目前业界常用的监控软件有很多,主流产品或以监控深度见长、或以监控广度见长。
- 关注监控广度的代表产品是 Prometheus,其特点是生态圈活跃,针对常见的互联网中间件(如 MySQL、Redis、Kafka、RocketMQ、MongoDB、ElasticSearch 等)均提供了现成的指标采集插件来进行监控。类似产品还有 Zabbix、Nagios 和 Open-Falcon。
- 关注监控深度的产品也有很多,如听云、Zipkin、OneAPM、PinPoint、SkyWalking。这类软件一般是探针型的,在应用性能监控方面提供了更深入的监控能力。
这些产品各有优势,也存在不足之处:
-
无法兼顾监控的广度和深度;
-
无法同时支持实时指标、调用链和日志三类类数据的采集,未考虑这三类功能的集成连通性,无法解决数据的时效、品控、对齐等问题。
平台统一意义
-
高可用、高性能
集中资源,重点设计和建设,提供稳定高效的监控报警系统
-
统一入口,方便易用
提供统一的界面和权限管理,方便开发人员配置报警,查看监控、分析数据、定位异常
-
集中维护,服务体验好
专人运维,积极响应开发需求,持续改进,提供更加专业的服务
-
建设监控报警数据中心,让数据更可用
集中收集数据,提供标准化数据消息,方便其他系统使用监控报警数据,完善生态
统一监控平台架构
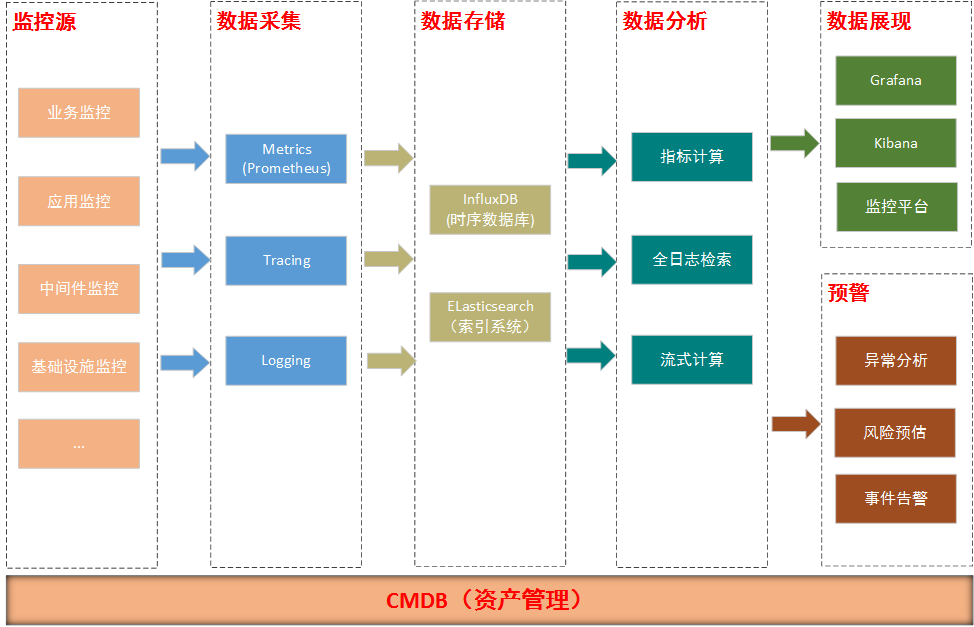
监控源
从层次上来分,大致可以分为三层,业务应用层、中间件层、基础设施层。业务应用层主要包括jvm、日志等,中间件层包括数据库、缓存、配置中心、等各种系统软件,基础设施层主要有物理机、虚拟机、容器、网络设备、存储设备等等。
数据采集
数据采集从指标上划分可以分为业务指标、应用指标、系统软件监控指标、系统指标。
应用监控指标如:可用性、异常、吞吐量、响应时间、当前等待笔数、资源占用率、请求量、日志大小、性能、队列深度、线程数、服务调用次数、访问量、服务可用性等
业务监控指标如大额流水、流水区域、流水明细、请求笔数、响应时间、响应笔数等,
系统监控指标如:CPU负载、内存负载、磁盘负载、网络IO、磁盘IO、tcp连接数、进程数等。
从采集方式来说通常可以分为接口采集、客户端agent采集、通过网络协议主动抓取(http、snmp等)
数据存储
采集到的数据一般都会存储到文件系统(如HDFS)、索引系统(如elasticsearch)、指标库(如influxdb)、消息队列(如kafka,做消息临时存储或者缓冲)、数据库(如mysql)
数据分析
针对采集到的数据,进行数据的处理。处理分两类:实时处理和批处理。技术包括Map/Reduce计算、全日志检索、流式计算、指标计算等,重点是根据不同的场景需求选择不同的计算方式。
数据展现
将处理的结果进行图表展现
预警
如果在数据处理过程发现了问题,则需要进行异常的分析、风险的预估以及事件的触发或告警。
CMDB(资产管理)
CMDB在统一监控平台中是很重要的一环,监控源虽然种类繁多,但是他们大都有着关系,如应用运行在运行环境中,应用的正常运行又依赖网络和存储设备,一个应用也会依赖于其他的应用(业务依赖),一旦其中任何一个环节出了问题,都会导致应用的不可用。CMDB除了存储软硬件资产外,还要存储这样一份资产间的关联关系,一个资产发生了故障,要能根据这个关系迅速得知哪些其他的资产会被影响,然后逐一解决问题。
业界方案
-
阿里
https://www.sohu.com/a/243512682_463994
-
在数据采集方面,原来采用是在机器上安装 Agent 的方式,而现在的系统则主要采集的是日志,包括:业务方的日志、系统的日志、消息队列的日志等。
-
从机器的管理角度出发,自行建立了内部的 CMDB,其中包括软件版本控制、发布打包等功能。
-
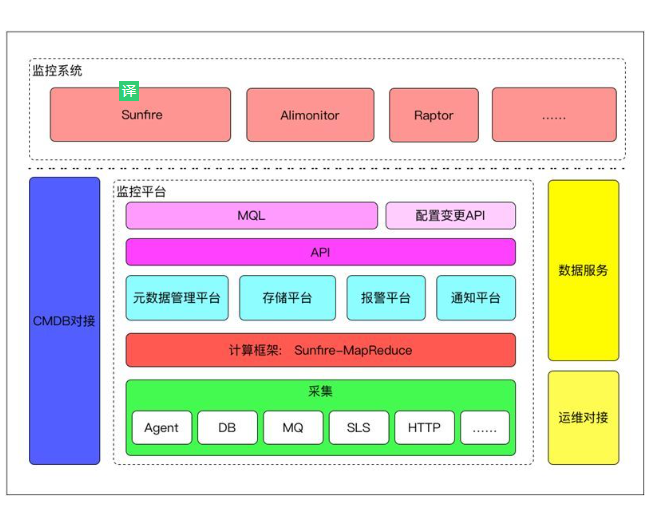
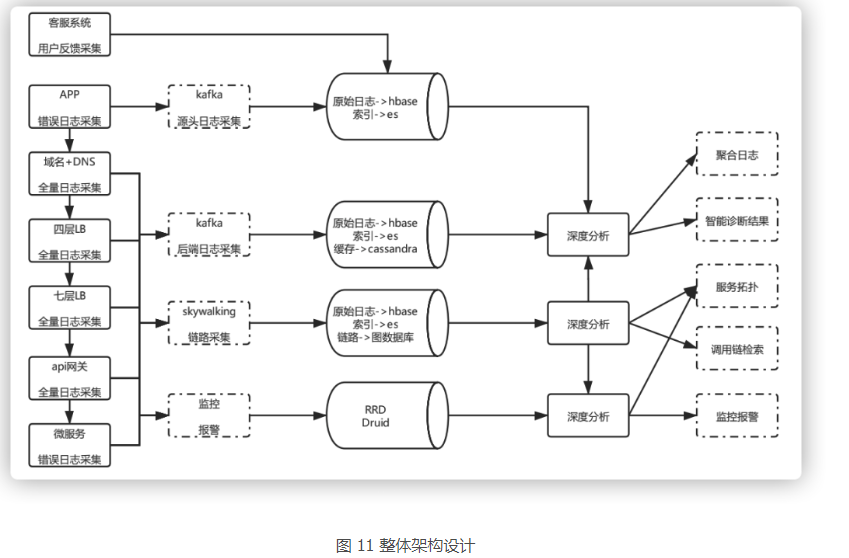
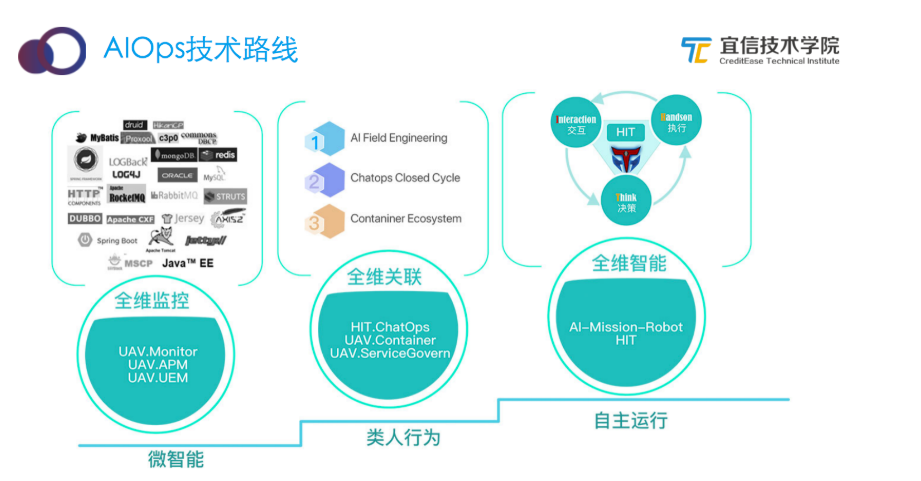
UAVStack 平台的总体技术架构:全维度监控 + 应用运维解决方案
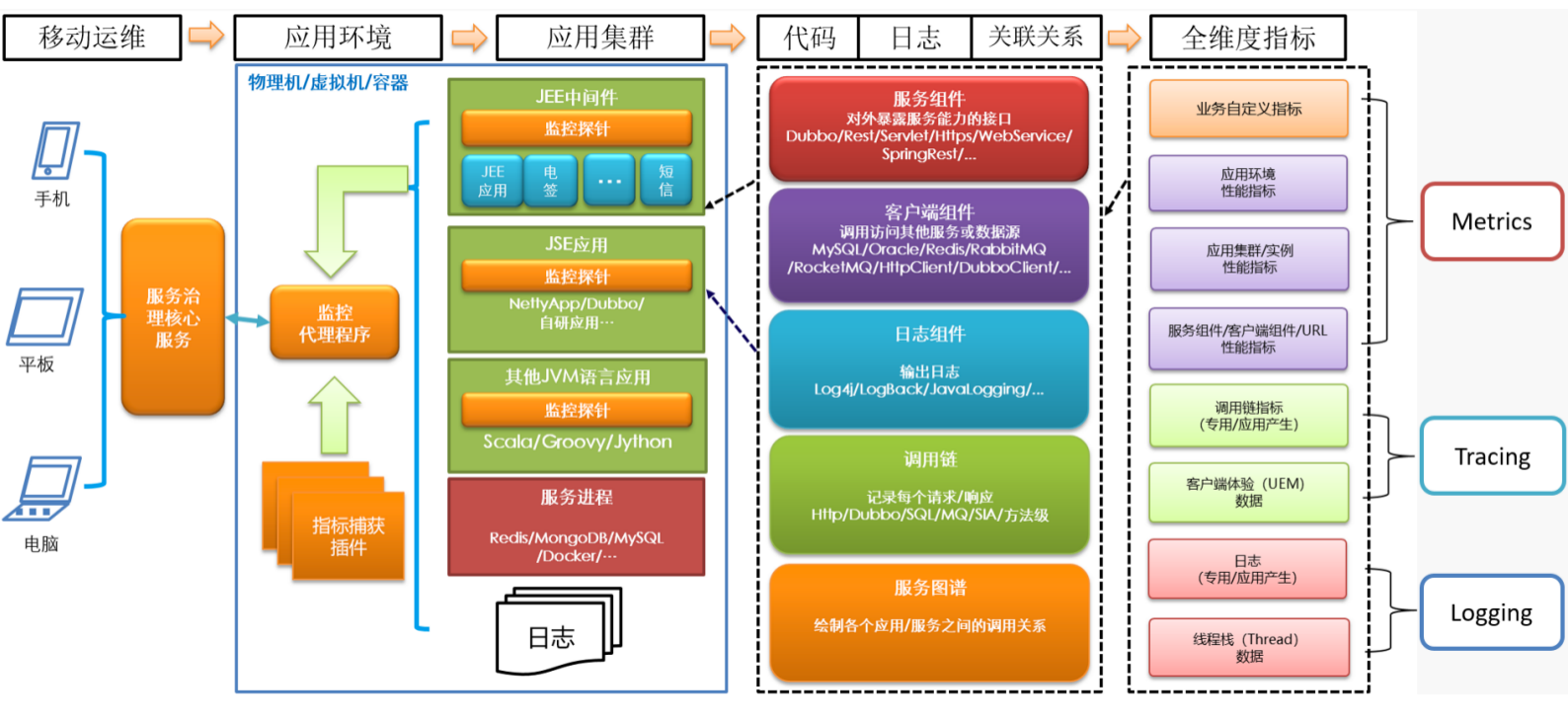
我司技术选型及方案
数据采集
指标采集
技术选型
prometheus
监控指标
- 接口请求统计: QPS、RT
- 业务jvm
- 中间件: redis、kafka、mongodb、memcached、mysql
- CPU、内存、Network、TCP
技术架构
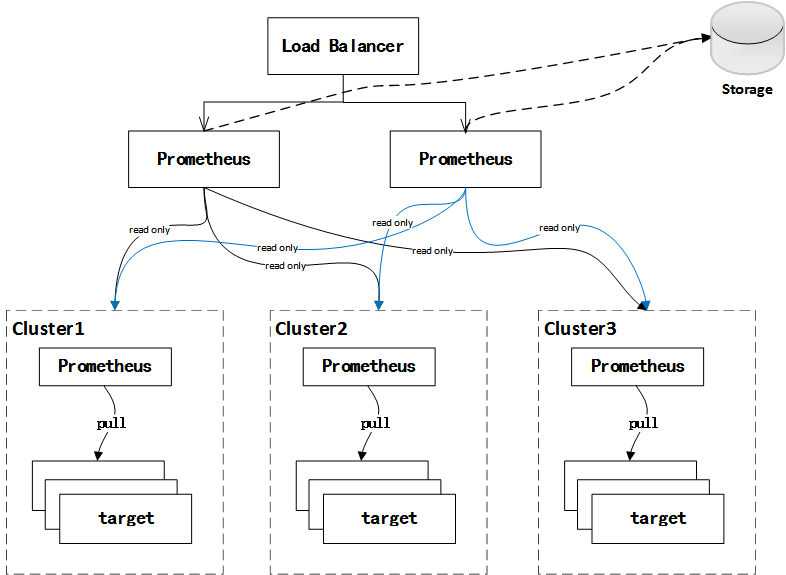
数据收集exporter
https://prometheus.io/docs/instrumenting/exporters/
链路采集
APM技术选型
| pinpoint | zipkin | jaeger | skywalking | |
|---|---|---|---|---|
| OpenTracing兼容 | 否 | 是 | 是 | 是 |
| 客户端支持语言 | java、php | java,c#,go,php等 | java,c#,go,php等 | Java, .NET Core, NodeJS and PHP |
| 存储 | hbase | ES,mysql,Cassandra,内存 | ES,kafka,Cassandra,内存 | ES,H2,mysql,TIDB,sharding sphere |
| 传输协议支持 | thrift | http,MQ | udp/http | gRPC |
| ui丰富程度 | 高 | 低 | 中 | 中 |
| 实现方式-代码侵入性 | 字节码注入,无侵入 | 拦截请求,侵入 | 拦截请求,侵入 | 字节码注入,无侵入 |
| 扩展性 | 低 | 高 | 高 | 中 |
| trace查询 | 不支持 | 支持 | 支持 | 支持 |
| 告警支持 | 支持 | 不支持 | 不支持 | 支持 |
| jvm监控 | 支持 | 不支持 | 不支持 | 支持 |
| 性能损失 | 高 | 中 | 中 | 低 |
根据上图以及基于我们现有业务选型:
skywalking
skywalking架构图
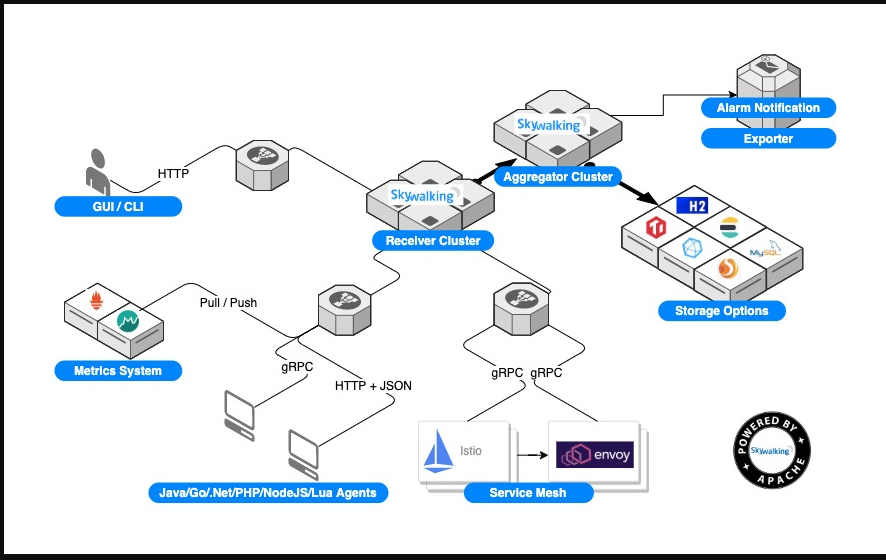
skywalking接入
skywalking Agent涉及到一些配置文件和jar,如果服务器部署需要把此文件夹写到服务器对应磁盘:
plugins包可以自定义:
skywalking采样率
3%
日志采集
主要采集的日志,包括:业务方的日志、系统的日志、消息队列的日志等。
日志的统计和告警功能:由 logging-statistics 程序从 Kafka 读取异常、关键字 日志,并以分钟为单位统计数量,生成指标写入prometheus,供后续统计展示和告警。
备注: 结合我司业务特点,目前对日志采集监控优先级比较低
数据存储
-
用于存储日志采集、链路采集
elasticsearch
-
用于存储指标采集
存储服务 支持模式 集群 部署 性能 社区活跃度Star influxdb read/write 否(收费) 简单 高 19.1K M3DB read/write 是 复杂 高 3.1K 基于我们先有以及未来1到2年指标数据量:
influxdb
influxdb压测情况
nfluxDB性能测试报告
被测环境:
CPU 内存 带宽 4核 16G 1Gbit/s 压测环境:
CPU 内存 带宽 2核 8G 1Gbit/s 测试程序:
从github上找的influxdata公司提供的两款测试工具
influx-stress 用于写入测试
influxdb-comparisons用于查询测试
测试场景:
写入测试 工具名称 influx-stress 工具github地址 https://github.com/influxdata/influx-stress 测试原理 该工具是通过go语言的fasthttp库编写的。1. 会在服务器上创建一个数据库stress2. 然后创建一个MEASUREMENT(类似关系数据库的表)名为ctr该表有time,n.some三个字段3. 不断的向stress数据库的ctr表插入数据,每次插入的数据都包含三个字段。每一条数据称为一个points。插入数据的方法是通过influxDB的HTTP API 发送请求(POST /write?db=stress) 测试命令 influx-stress insert -r 60s –strict –pps 200000 –host http://10.XX.XX.XX:8086 测试程序运行结果 Points Per Second(发起请求) Write Throughput(points/s)(数据库实际处理结果) CPU平均利用率 200000 199713 33% 300000 299280 45% 400000 392873 62% 500000 491135 80% 600000 593542 90% 650000 606036 93% 700000 613791 95% 测试结论:最大的吞吐量为每秒写入60万条数据。这之后,每秒发送的points再多,吞吐量也不会增加,同时CPU利用率已达90%。
数据展现
grafana+ pass平台
预警