故障处理手册
概述及目标
本文档详细描述了故障处理操作,通过故障处理,可及时解决系统在运行期间发生的故障,使系统能够快速恢复正常运行。
范围
本文档主要适用于以下人员:
- 运维工程师
- 开发工程师
故障发现
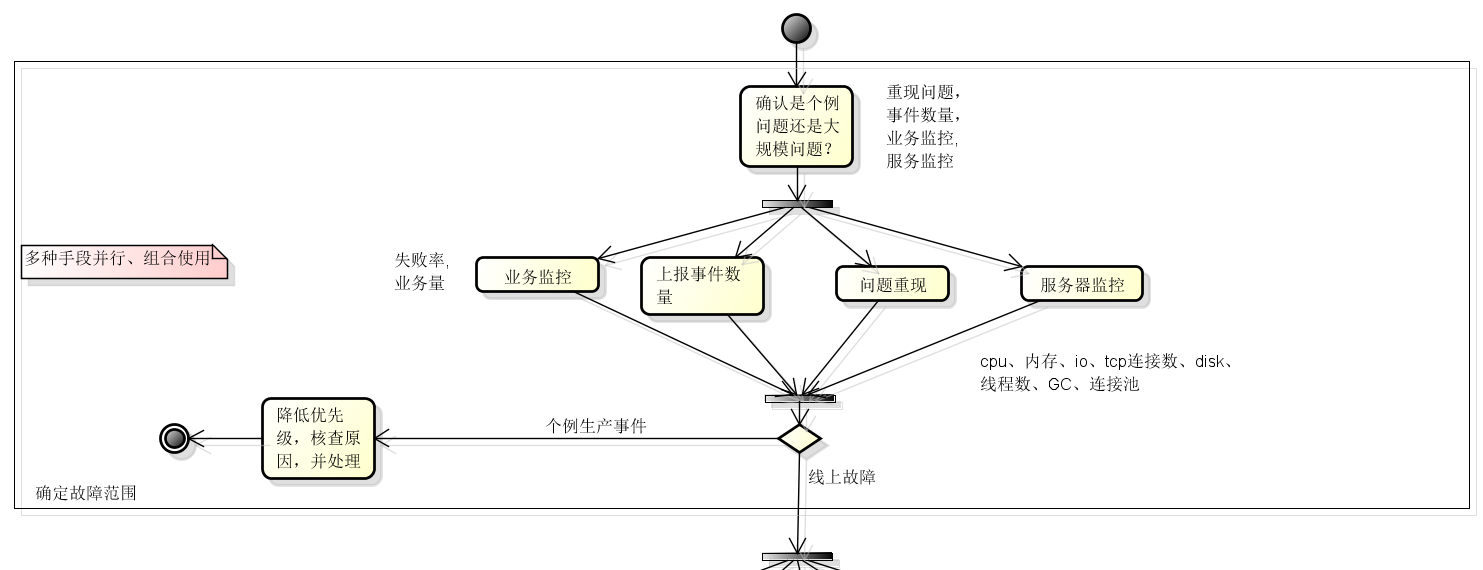
线上故障一般可以通过如下几种途径传递到开发/运维人员手中,按照从上到下的顺序,故障的严重程度依次变高。
- 主动发现
- 可能是开发或者运维不经意间查看生产环境的error日志,或者例行检查监控项时,看到了一些异常的现象,进而发现了故障;
- 系统监控告警
- 通常包括cpu、内存、io、tcp连接数、disk、线程数、GC、连接池、网关(gateway)等各个服务器指标异常,
- 可能是服务器出现了异常,但是业务还未受到大面积影响;
- 业务监控告警
- 如业务请求出现大量5XX、4XX,则意味中系统的异常已经很严重,影响了业务处理;
- 关联系统故障追溯
- 上游系统或者下游系统的故障处理追溯,可能和本系统有关系,而且情况已经变得很糟糕了,需要快速定位;
- 生产事件上报
- 通常业务异常带来的影响传递到用户,再从用户传递到客服人员,再到技术人员手里,会存在一定时延,所以一旦有生产事件上报,这个时候严重性已经到了最高,技术人员的压力也会增大,因为会有领导的关注,产品经理的询问和催促,客户人员的焦虑带来的压力
上述途径传递过来的信息仅仅只是线上故障苗头,并非一定就发生了大规模的线上故障,所以首先需要确认的是这是不是一次线上故障?还是只是个例生产问题?是否和本系统有关系?
- 一般来讲:‘系统监控告警’和‘业务监控告警’的情况下,大部分都和本系统有关,且可能是线上故障;
- 而‘主动发现’和**‘生产事件上报’则需要做甄别,可以根据上报事件个数或者问题复现的方式来评估是否是大规模线上故障,或者跟踪日志信息或者特定用户问题追溯来确定。
- 至于‘关联系统故障追溯’的情况,首先不要慌,先从宏观上确定本系统服务正常,一般可以检查是否有服务器监控报警,是否有业务监控报警等来确定,如果上游或者下游提供了日志,可以通过日志进行追踪,从而确定本系统是否存在故障。
TIP: 因此在得到一些线上故障苗头之后,可以通过以下途径确定是否是线上故障:业务监控告警、上报事件个数、问题重现、服务器监控等。这些途径可以并行进行,灵活组合,有时候一个手段就能确定,有时候需要组合多个手段予以判定。
故障处理原则
故障分析、定位和处理原则
- 以尽快恢复系统为原则。
- 在无法快速找到故障原因的时候,需要果断跳过故障定位环节,直接进行故障排除,比如采用服务降级、服务器扩容等手段,确保对线上服务降到最低且可控。等到线上服务’撑’过去之后,我们再慢慢定位故障原因,根本上解决问题。
- 定位故障时,应及时采集故障数据信息,并尽量将采集到的故障数据信息保存在移动存储介质中或网络中其它计算机中,便于事后分析
- 在确定故障处理的方案时,应先评估影响,优先保证业务的正常。
定位处理前注意事项
- 应先分析故障现象,定位原因后再进行处理。在原因不明的情况下应避免盲目操作,导致问题扩大化。
- 在处理故障前,需要保留好故障现场的任何记录,不能随意删除数据或日志。
- 在进行任何修改前,应先通过脚本导出、手工备份等方式备份数据。
- 在维护过程中遇到的任何问题,应详细记录各种原始信息。
- 所有的重大操作,如重启进程均应作记录,并在操作前仔细确认操作的可行性,在作好相应的备份、应急和安全措施后,方可由有资格的操作人员执行。
- 在系统恢复后,必须对运行情况进行观察,确认故障已经排除并及时填写相关的处理报告。
- 慎重使用高危操作及命令。
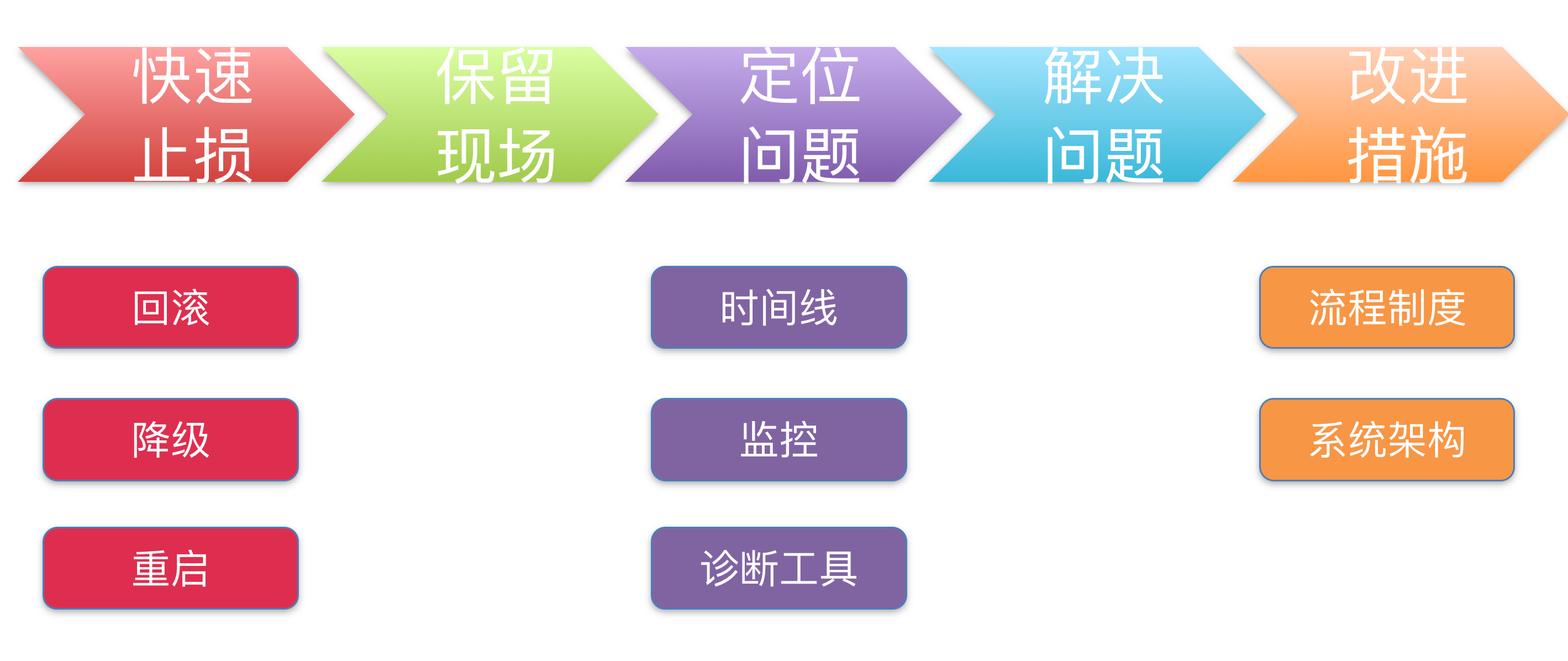
故障处理一般流程
内容小结
线上故障不可避免,任何系统都可能会因为内外部原因出现故障。比如:程序BUG、硬盘故障、网络中断等。
一般故障发生及解决是一个持续过程,这个过程包括事前、事中、事后。针对3个过程,我们都总结了对应的手段:
- **事前:**通过必要监控手段、提前感知到系统异常。一是把故障扼杀在摇篮中;二是出现故障能方便快速定位问题,找到解决方案
- **事中:**出现故障后,要快速止损,避免对系统造成更严重后果。比如:可以通过降级、熔断、扩容等手段
- **事后:**要对故障进行复盘,多问为什么会出现故障。然后制定改进措施并落地