kafka分布式原理探究
前言
Apache Kafka是一款分布式流处理框架,用于实时构建流处理应用。同时它有一个广为人知的能力,作为一款分布式消息引擎被各大公司广泛使用。
既然作为分布式框架、那么分布式系统一些特性:数据分区、数据复制、以及分布式可靠性,在Kafka中又是如何实现的呢?接下来,我将带你逐步探究这些特性,并分析Kafka实现原理。
Kafka体系架构
在探究分布式原理之前,我们先了解Kafka体系架构、以及体系架构下一些名词解释。
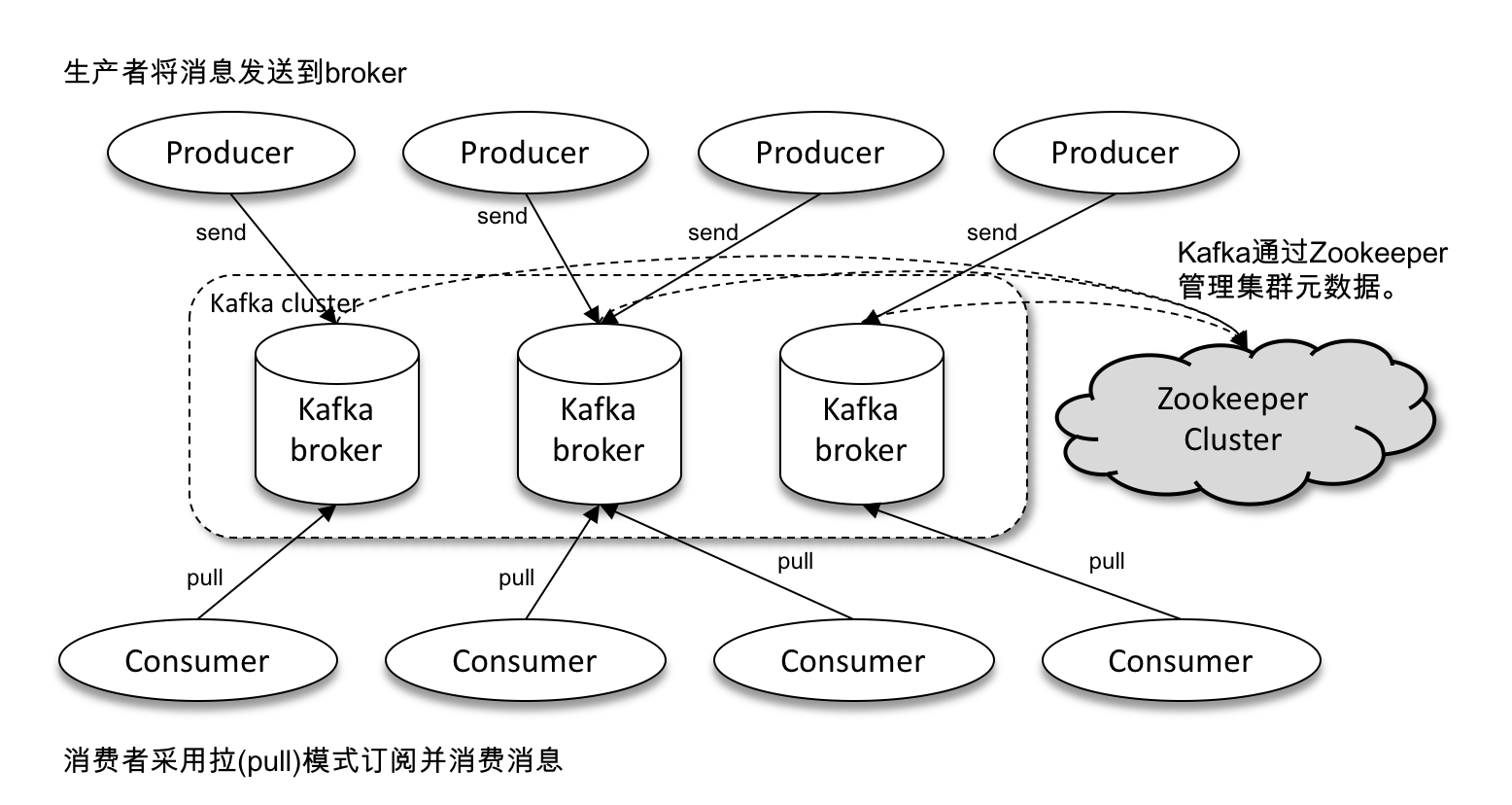
整个Kafka体系结构中包含如下术语:
-
Producer: 生产者
也就是发送消息的一方。生产者是负责创建消息并向kafka写入事件的客户端应用程序
-
Consumer: 消息者
也就是消息接受的一方。消费者是连接到kafka并接受消息,然后进行相应业务逻辑处理的客户端应用程序
-
Broker: 服务代理节点
接收生产者发送来的消息,并把消息存储在本地磁盘;发送消息给消息者,并记录消费者消费offset。通常一台机器部署一个Broker节点,多台机器多个Broker节点组成kafka集群。
除了上述这些术语,kafka还有两个特别重要的概念:主题(Topic)和分区(Partition)。
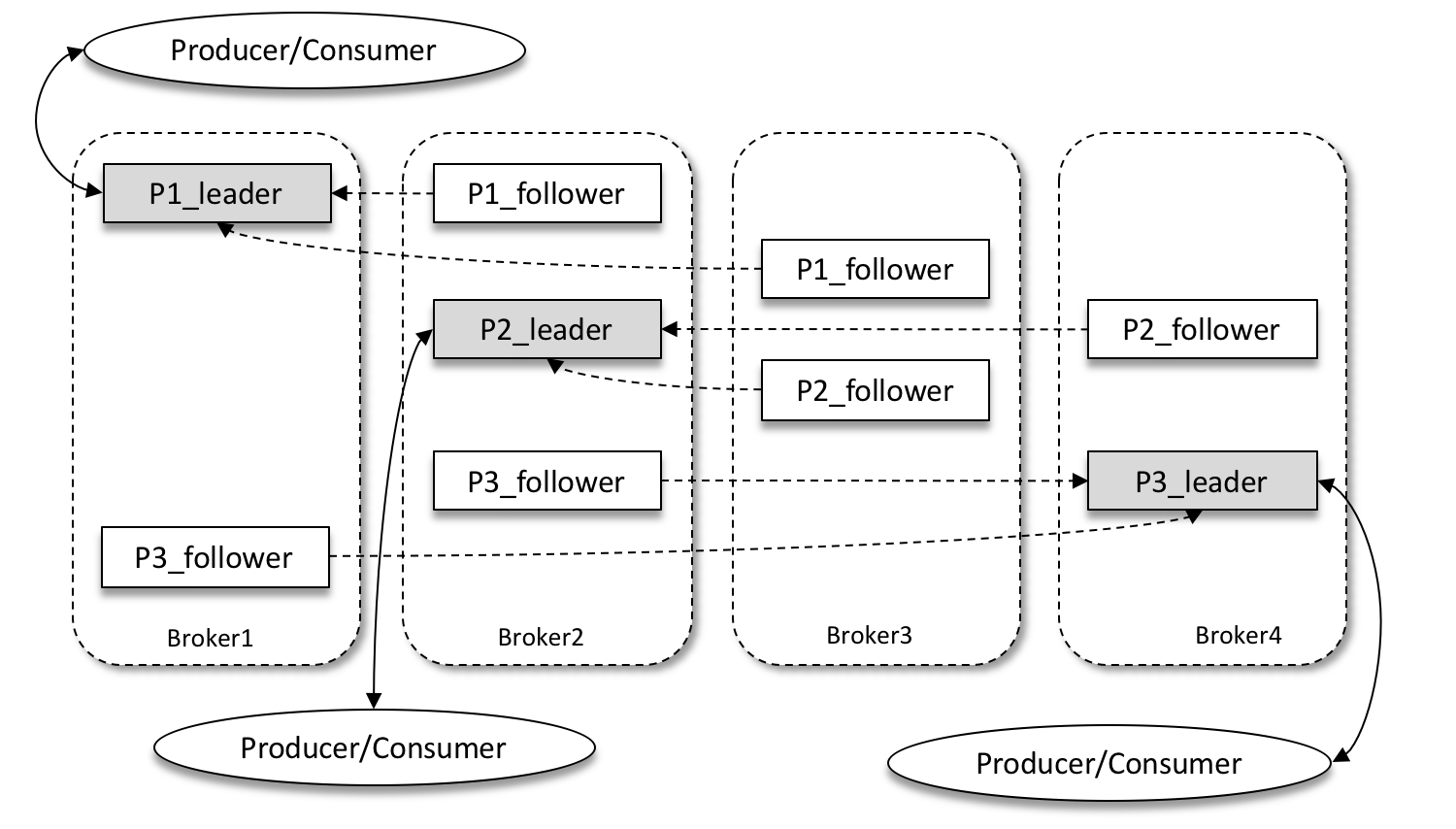
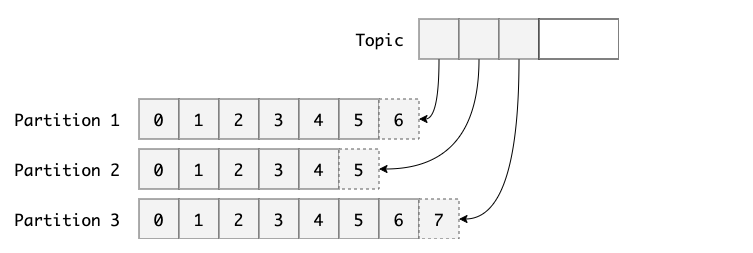
什么是主题(Topic)
主题是一个逻辑的概念,Kafka中可以存在多个topic,每个topic可以认为是同一类的消息。生产者负责将消息发送到特定topic,而消费者负责订阅topic并进行消费。
kafka主题概念让消息系统更灵活。按照网络消息的传送方式,双端需要定义消息格式,比如:消息头长度、消息头、消息长度、消息(消息格式)。如果没有主题,我们就需要在消息格式进行约定,同时消息进行编解码时需要按照约定进行处理。有了主题后,同一类消息发送到一个主题,让我们在业务中简化了对消息分类的处理。
上图kafka集群定义了3个主题,分别是:P1、P2、P3。
什么是分区(Partition)
一个主题上,可以细分为多个分区。从分区视角看,一个分区只属于一个主题,所以通常把分区也叫做主题分区(Topic-Partition)。
同一个主题下包含的分区的数据是不同的,也就说当Producer客户端应用程序发送消息时,需要判断消息发送到哪个分区上。在kafka上写入主题的消息会被平均分配到其中一个分区。
如果出现主题分区设置过小,消息过大时会导致分区所在机器I/O将会成为这个主题的性能瓶颈,可以通过修改分区数实现水平扩展
什么是副本(Replica)
Kafka为分区引入多副本机制(Replica), 通过副本数可以提升容灾能力。同一分区副本数保存相同消息,副本之间是一主多从关系,其中Leader副本负责读写请求,Follower副本只负责与Leader副本消息同步,副本位于不同Broker上,当Leader副本出现故障时,从Follower副本重新选举新的副本提供对外服务。
为什么要设计为分布式架构?
前面提到过kafka的主题分区(Topic-Partition)。那么在Kafka中为啥要设置主题分区?
kafka最初就是用来处理海量消息而设计的,而处理海量数据必须思考所有分布式都面临问题:
-
处理海量数据CPU、内存、磁盘如果使用大型机,成本上不可承受。
-
如果我们想处理TB级别数据,即使单台大型机也不足以承载海量数据
而分布式系统,通过普通单机集群就能满足我们需求:
-
通过可伸缩上百、上千台节点处理PB数据
-
这些节点都是采用廉价的PC架构搭建起来
-
整个集群,开发者来说都是把数据中心当作是一台计算机操作
通过以上一些重要概念,我们可以定义分布式系统一些特性:
- 可靠性
- 可扩展性
- 可维护性
数据分区
前面说到Kafka作为一个分布式的数据系统的可扩展性。在大数据场景下,单个节点不能存储所有数据,于是就有了数据分区。那么Kafka是如何处理数据分区的?
分区创建/修改
可以通过kafka只带工具创建或者修改主题分区
创建
bin/kafka-topic.sh --zookeeper localhost:2181/kafka --create --topic topic-examples --replication-factor 2 --partitions 4
创建topic-examples的主题,为这个主题定义4个分区,每个分区包含2个副本(leader副本/follower副本)**
修改
bin/kafka-topic.sh --zookeeper localhost:2181/kafka --alter --topic topic-examples --partitions 5
目前Kafka不支持通
alter命令减少分区,那么为什么不支持减少?
- 删除分区后,分区中的消息如何处理?如何随着分区一起消失,则分区可靠性得不到保障;
- 如果需要保留又得考虑如何保留,如果按照一定规则分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间需要考虑分区以及副本状态切换等问题
如何真需要减少分区,一般做法是重新创建一个分区数较小的主题,然后将现有主题中的消息复制过去,Apache Kafka 社区提供的 MirrorMaker 工具,它可以帮我们实现消息或数据从一个集群到另一个集群的拷贝
分区重分配
虽然kafka不支持通过一般命令减少分区,但是当集群中一个节点出现故障需要下线时,为了保障分区上的数据,我们需要通过某种方式将该节点上的分区数据迁移到其他可用节点。
Kafka提供了Kafka-reassign-partitions.sh脚本来执行分区重分配工作,它可以在集群扩容、Broker节点失效的场景下对分区进行迁移。
我们分三步来演示分区的重分配
-
首先在一个由3个节点(broker 0 、broker 1、broker 2)组成的集群中创建一个主题,主题包含4个分区和2个副本
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-examples --replication-factor 2 --partitions 4 Created topic topic-examples. -
查看主题
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-examples Topic: topic-examples TopicId: QgJg_d0gSV6O7-gQutDv3w PartitionCount: 4 ReplicationFactor: 1 Configs: Topic: topic-examples Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2 Topic: topic-examples Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: topic-examples Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: topic-examples Partition: 3 Leader: 0 Replicas: 0,1 Isr: 0,1 -
出于某种原因,我需要下线
broker 1节点,在此之前需要将其上的分区副本迁移出去**第一步:**创建一个需要迁移的主题
{ "topics":[ { "topic":"topic-examples" } ], "version":1 }**第二步:**根据这个JSON文件和指定要分配broker节点列表生产一份候选的重分配方案:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --generate --topics-to-move-json-file reassign.json --broker-list 0,2**第三步:**根据第二步保存的json文件,执行具体重分配动作:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file new.json --execute
分区重分配基本原理:先通过控制器为每个副本添加新副本(增加副本因子),新的副本将从分区的Leader副本复制所有数据。在复制完成后,控制器将旧副本从副本清单中移除(恢复原先的副本因子)
写入分区
Producer创建完消息后,需要把消息发送到broker。消息在通过send()方法到broker过程中需要经过拦截器(Interceptor)、序列化(Serializer)和分区器(Partitioner)。
分区器是指kafka生产者通过分区算法策略,决定将生产者消息发送到哪个分区
Kafka 中提供的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了 org.apache.kafka.clients.producer.Partitioner 接口,这个接口中定义了2个方法,具体如下所示
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
public void close();
比较常见分区策略:
轮询策略
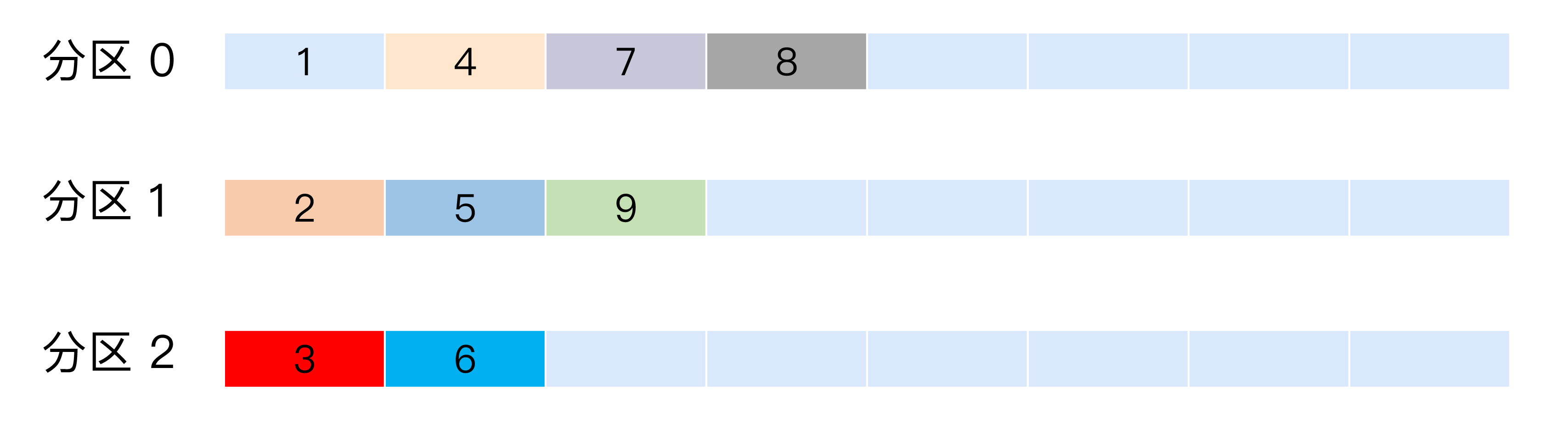
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
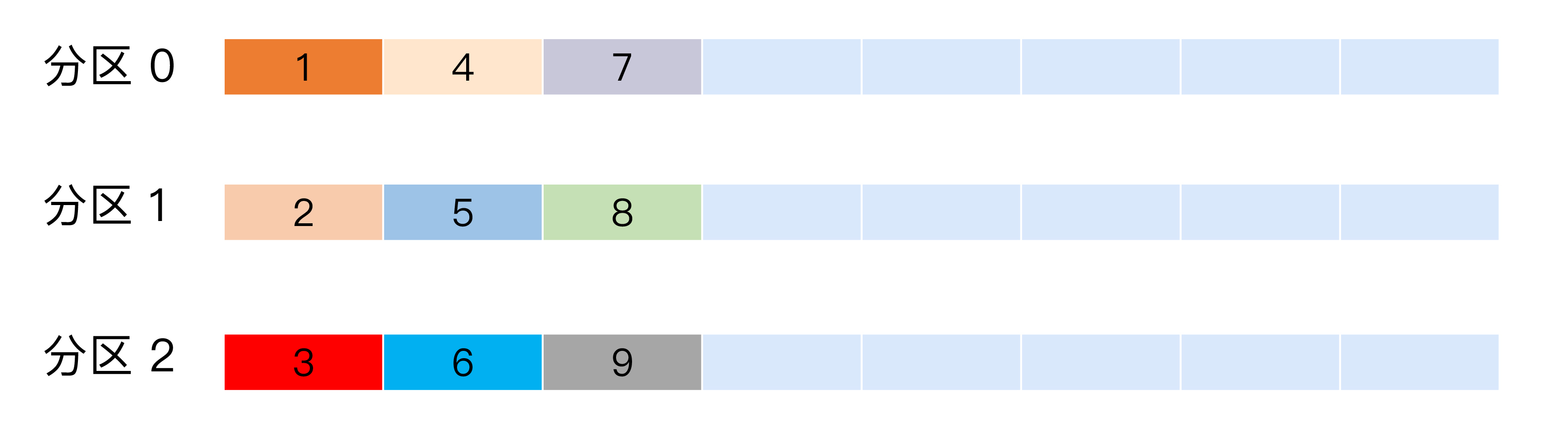
这就是所谓的轮询策略,轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示
如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数
小结
通过以上学习,我们大致了解kafka是如何分区可扩展性的,首先在创建主题时设置多个分区数,这样分区就平均分布到集群broker。其次,要是通过生产者分区器来计算消息要写入到哪个分区。最后,节点如果出现故障,可以通过分区重分配迁移数据。
数据复制
前文说了kakfa副本机制用于满足分布式系统可靠性,数据副本一般是在不同节点持久化同一份数据。
新的kafka版本采用分布式共识算法raft,自动实现数据复制、主从副本切换等状态改变。当Leader副本所在节点出现故障,存储的数据丢失时,可以从其他副本上读取该数据。
raft算法是一个基于领导者的机制:Leader副本负责读写、Follower副本复制同步Leader副本数据。当Leader副本挂掉后,通过分布式共识算法从Follower副本列表中选举新的Leader副本,老Leader副本恢复正常后,只能作为Follower副本加入集群
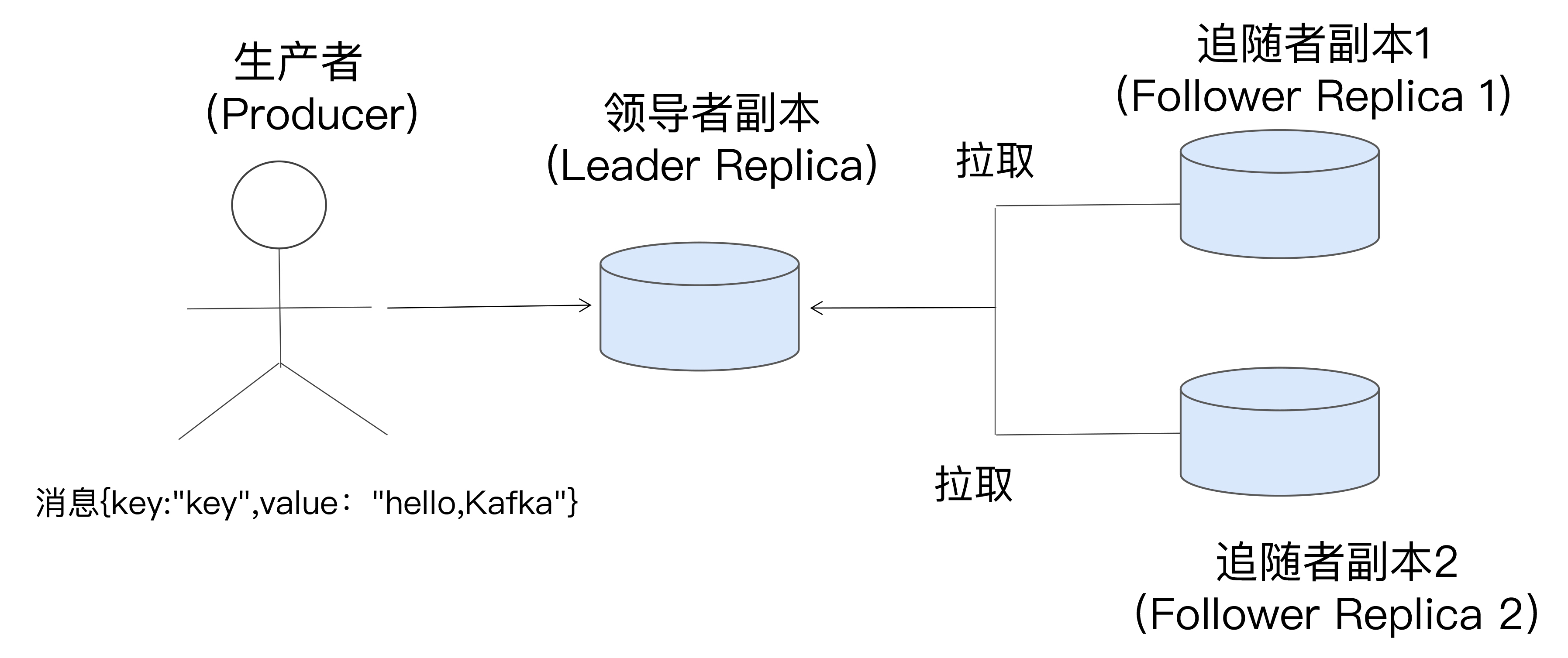
如下图,某个分区有3个副本分别位于broker 0、 broker 1、broker 2节点中,其中带阴影的表示Leader副本
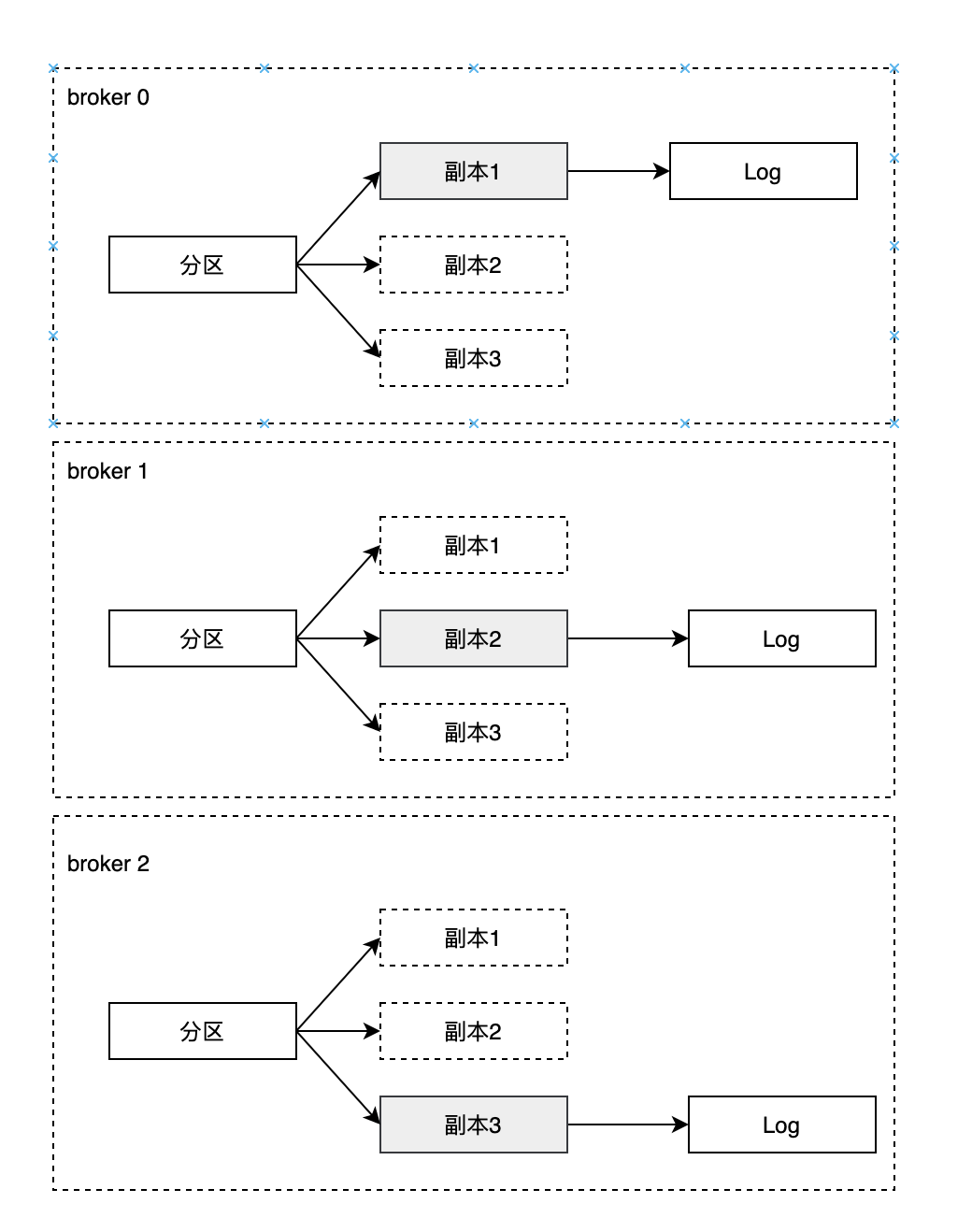
- 一个分区中包含一个或者多个副本,其中一个为leader副本,其余为follower副本,各个副本位于不同broker节点中。只有Leader副本对外提供副本,follower副本只负责数据同步
- 分区中所有副本统称为AR(Assigned Replicas),而ISR是指与Leader副本保存同步状态的副本集合,极端情况下ISR副本中可能只有Leader副本
- LEO标识每个分区中最后一条消息的下一个位置,分区的每个副本都有自己的LEO,ISR中最小的LEO既为HW(俗称高水位),消费者只能拉去到HW之前的消息
内容总结
kafka通过主题下创建分区满足分布式的可扩展性;增对每个分区按照一主多从架构创建副本满足分布式系统可靠性;同时broker底层通过分布式共识算法raft,自动选举副本、同步数据,同时通过封装客户端应用程序满足分布式的可维护性。